
A common task for data folks is loading comma separated values files into databases. It can be tedious, having to figure out column layouts, data formats, and sorting bad data. This sort of Extract, Transform, and Load (ETL) task is something we would do in SSIS or a similar loading tool, but those tools require us to review the data and have a good idea of what the staging table will look like. Most of the time with CSVs, we just need a quick dump of the file into a database table so we can work with it using T-SQL, which means that I don’t want to spend a lot of time figuring out what a stage table is going to look like.
I know SQL Server Management Studio will try and help you out with the Import Data task. I have used this pretty frequently myself. However, like any other GUI tool out there, you can not automate it. It builds a one time SSIS package (which you can save) and executes it, but if it does not save much time if I have to load multiple CSV files with differing formats.
We all know my weapon of choice is Powershell. I am sure there are other approaches to this problem and my ETL/BI pals are probably reading this post in dismay (if they are reading it at all!). However, I’m pretty comfortable with the patterns in Powershell to script this process, letting me quickly load multiple CSV files without having to do a lot of work.
All Around the Table
The challenge is getting the staging table in place. We need a process that can read the CSV header and build a CREATE TABLE statement for us. Once we have that, the load is actually pretty easy. Assuming the CSV has a header row, I then use this bit of Powershell code to figure out the different columns I’m going to load into:
$source = <Path to your source file>
$Header = (Get-Content $source | Select-Object -First 1).Split(',')
Two lines of Powershell and now I have a collection of all my column names as a string array. This is where the fun begins. Now, I can not assume that the column headers will play nice as SQL column names, so I need to do a little hygiene work. I will loop through the collection and strip out any non-alphanumeric characters:
$CleanHeader = @()
foreach($h in $Header){
$CleanValue = $h -Replace '[^a-zA-Z0-9_]',''
$CleanHeader += $CleanValue
}
I could use ForEach-Object here to simplify the code, but I expand it out in a foreach loop because I might add some other logic to the header name clean up. I want to keep it simple for this example. The result is a new collection that has names I can use to create a staging table.
Next up, I will take this new collection and build out a SQL statement. This is a matter of looping through the CleanHeader collection and using those values. Since we can’t really tell what the format will be, each table column will be VARCHAR(255).
$StagingTableName = ‘CSVFileLoad’
$sql = @("IF EXISTS (SELECT 1 FROM sys.tables WHERE name = '$StagingTableName') DROP TABLE [$StagingTableName];")
$sql += ("CREATE TABLE [$StagingTableName]($($CleanHeader[0]) VARCHAR(255)")
$CleanHeader[1..$CleanHeader.Length] | ForEach-Object {$sql += ",$_ VARCHAR(255)"}
$sql += ");"
The SQL format is a typical pattern:
- If the table name already exists, drop it (we’re doing a drop and replace of the data).
- Grab the very first column name in the collection and use it to start the CREATE TABLE.
- Loop through the remaining column names, putting a comma in front of each column.
- Close the CREATE TABLE statement with a parentheses and semicolon.
This block of code is the key, allowing me to create any table structure to import my data with. Once I have it, I just execute it using Invoke-SqlCmd as I would any other T-SQL statement, and my staging table is now in place.
Stick the Landing
Once the staging table is in place, the load is actually fairly simple. You have lots of options, but the easiest one for my money is to build a BCP call and execute that. BCP is a simple utility that has been around for a while, mostly because it is effective. The build is not difficult:
$cmd = "bcp '$Database.dbo.[$StagingTableName]' in '$Source' -S'$SQLServerName' -F2 -T -c -t','" Invoke-Expression $cmd
For those unfamiliar with the BCP syntax, all I do is declare the destination table, the key word ‘in’ to declare that I am loading data from a file to a SQL Server table, and then the SQL Server name. The remaining parameters set the following load options:
- -F2: Start the load with the second row, skipping the header
- -T: Use windows authentication to connect
- -c: The input file is character data
- -t’,’: The column terminator is a comma
This is how I do it, but there are plenty of other options. Allen White(@SqlRunr) has written about using the .Net methods to perform a Bulk Load. You could also use the BULK INSERT command run from an Invoke-SqlCmd call. There are probably a dozen ways to skin this particular cat. The choice is up to you.
Now For Your Parting Gift
As with many of these patterns that I blog about, I have a function I have written around it. This one is Import-CsvToSqlTable. This function has some additional pieces that are best discussed by reviewing the parameters:
- InstanceName – SQL Server Instance you are going to load to.
- Database – Database name you are going to load to.
- SourceFile – Source file to load
- SqlDataType – Data type the staging table columns will be created as. Defaults as VARCHAR(255).
- StagingTableName – Table name you will create and load into.
- Append – If declared, the staging table will not be dropped if it already exists.
The function wraps up all the different pieces of what we talked about above. With it wrapped in a function, we now can call it for a simple data load. For this load, I am using a file from https://catalog.data.gov/ for New York City demographics:

Nothing fancy and the output shows the instance, database, table, and count of rows in that table. If we look in SQL Server, we will see the table created with VARCHAR(255) columns as expected:

We can do more, though. Let’s say we know that the file contains numbers in all the columns. It might make more sense to load them into a FLOAT or a NUMERIC datatype. We’ll declare that now. I’m also going to declare the -Verbose so I can see the detail of how the function is processing the import:
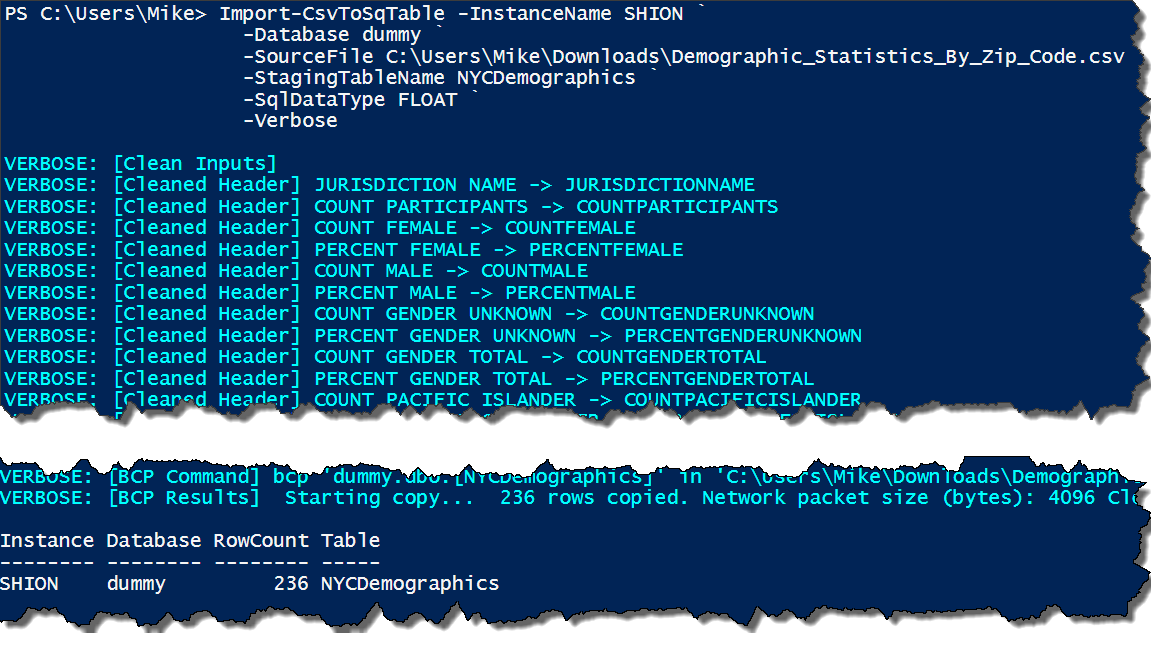

With the right parameters, not only do we have control over what we create, but we can see how it’s created and loaded into SQL Server. This can help with troubleshooting in case we try and load the wrong data type or there is some other error for the load.
This function can be useful for quick and dirty data loads, importing CSVs that we don’t want to waste a lot of time figuring out. I wrote it for this express purpose, because I did not want to get tied up clicking on buttons in the Import Data Wizard. However, I definitely do not recommend this as a full on replacement for ongoing ETL processes and standardized data loads. For any ongoing process where you know the format of your data files, there are much better options and approaches. As with any task, it is important that you use the right tool for the job, but it never hurts to understand your options.











 I’m tweeting!
I’m tweeting!