
The final piece of the Availability Group puzzle is managing databases in them. Managing is typically adding and removing databases, but we also can start and stop the replication of data to other nodes. These can all be handled via T-SQL and cmdlets contained within the SQLPS module.
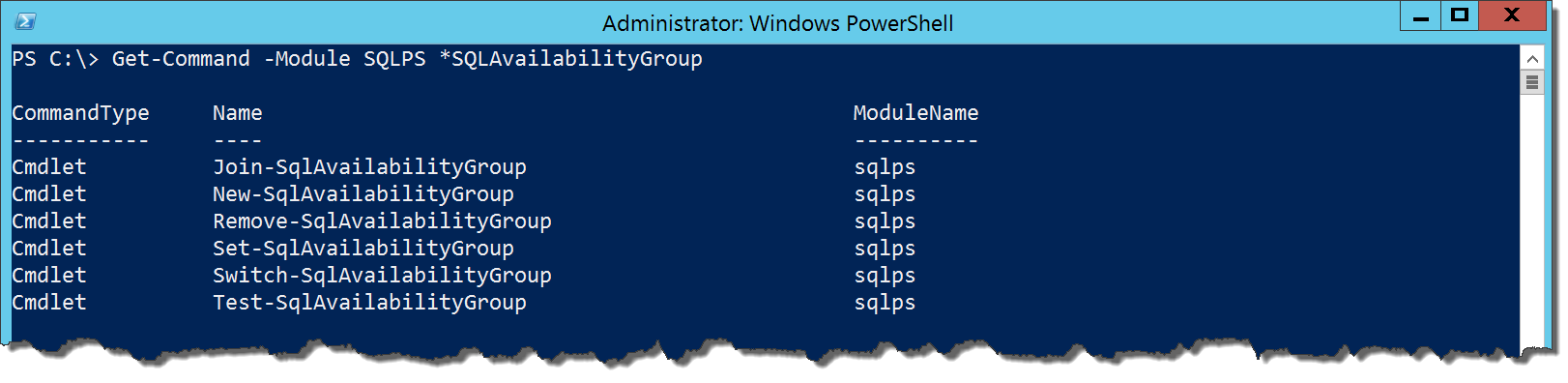
There are four cmdlets in the module for database management in Availability Groups:
Get-Command -Module SQLPS *SqlAvailabilityDatabase
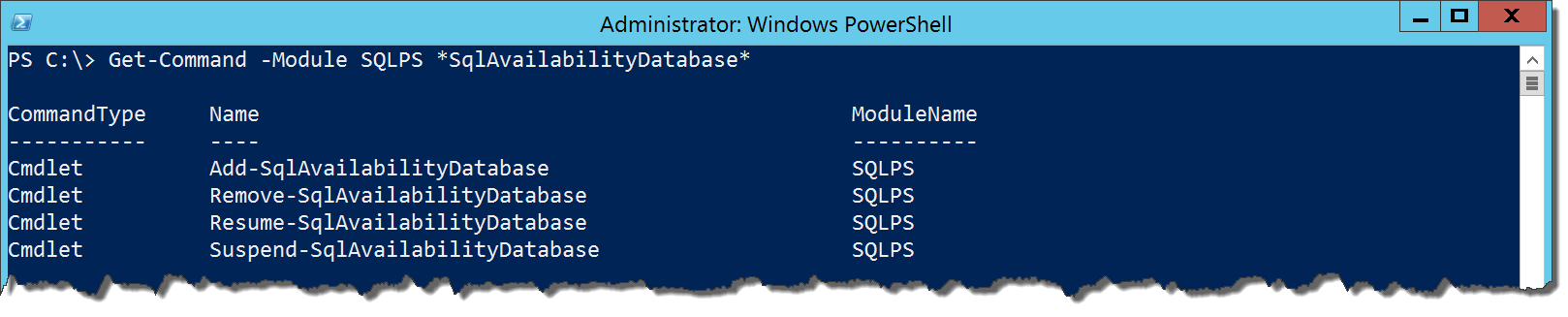
These are easily identifiable based on their names. Since adding and removing a database from an AG is the most common set of tasks, we’ll first look at Add-SqlAvailabilityDatabase. Typical of the other SQLPS cmdlets for AGs, it will take the path or Smo.AvailabilityGroup object for the node where you are adding the database. It will also take the database name. Simple enough, right? What’s interesting is how the behavior of the cmdlet differs depending on where you execute it.
Let’s see what happens if we use the cmdlet for a database on the primary node. Whenever we add a database, we always have to add it to the primary node first. In order to demonstrate the differences, I’ll run the example with the -Script switch so we can see the T-SQL it will execute:
Add-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\KIRK\DEFAULT\AvailabilityGroups\ENTERPRISE -Database AdventureWorks2012 -Script

This output is exactly what we would expect if we followed the Microsoft documentation on adding a database to an AG. This further reinforces that cmdlets are simply wrappers for T-SQL. Now what if we ran this same command on a secondary node:
Add-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\SPOCK\DEFAULT\AvailabilityGroups\ENTERPRISE -Database AdventureWorks2012 -Script
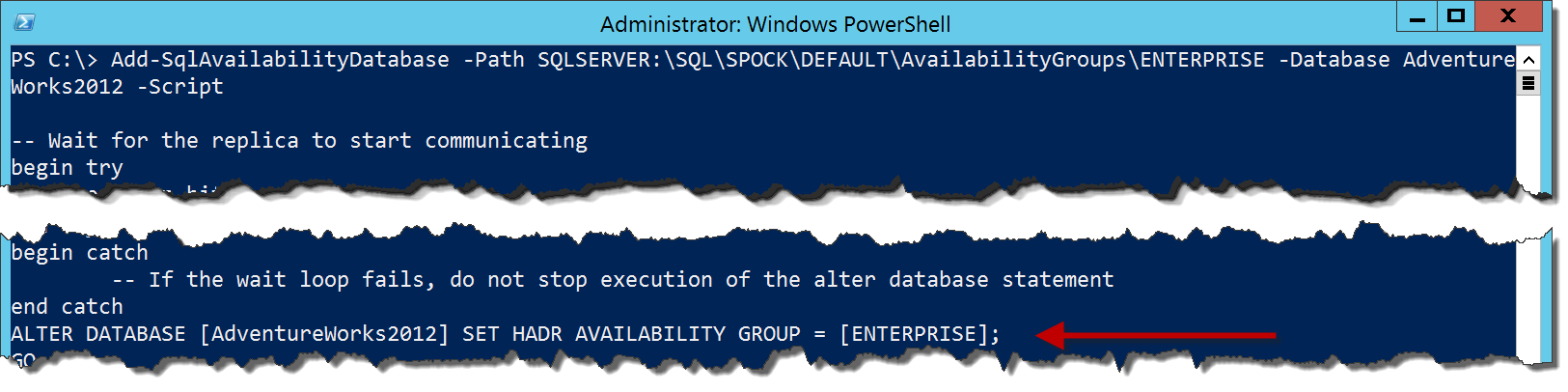
There is a lot more here, but I’ve cut out a lot of the extra stuff and called out the important bit, which is an ALTER DATABASE command instead of the ALTER AVAILABILITY GROUP call we need to make on the primary node. The cut out material is T-SQL that validates that there is an AG for the secondary node to join, then runs the T-SQL for joining a secondary.
This is one of the handier bits of code within the SQLPS module. It is a little annoying to remember that there are two different pieces of T-SQL syntax for adding a database to an AG. The SQLPS cmdlets account for that by wrapping up the logic in a single call and sorting out the correct command for you.
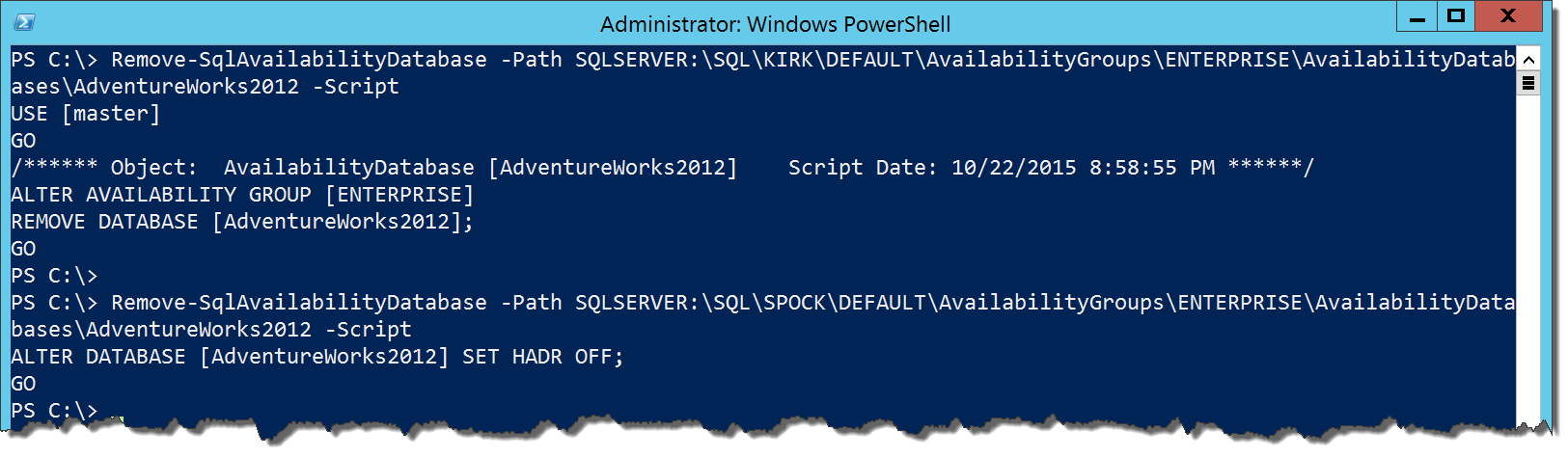
The Remove-SqlAvailabilityDatabase cmdlet works in a similar fashion. The main difference is that our reference is now to a Smo.AvailabilityDatabase object, found in AvailabilityDatabases under your AG in the provider. Yes, I hear ya’, how many different object paths do we need to keep track of? Anyway, the cmdlet will take a different action depending on which node it executes on:
Remove-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\KIRK\DEFAULT\AvailabilityGroups\ENTERPRISE\AvailabilityDatabases\AdventureWorks2012 -Script Remove-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\SPOCK\DEFAULT\AvailabilityGroups\ENTERPRISE\AvailabilityDatabases\AdventureWorks2012 -Script
The final two cmdlets will control data replication. We can suspend data replication in an availability database when necessary using the Suspend-SqlAvailabilityDatabase and Resume-SqlAvailabilityDatabase cmdlets. They serve as wrappers for ALTER DATABASE [] SET HADR SUSPEND/RESUME and follow the same restrictions. You call them with the availability database path or using the Smo.AvailabilityDatabase object for the database you want to alter:
Suspend-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\KIRK\DEFAULT\AvailabilityGroups\ENTERPRISE\AvailabilityDatabases\AdventureWorks2012 Resume-SqlAvailabilityDatabase -Path SQLSERVER:\SQL\KIRK\DEFAULT\AvailabilityGroups\ENTERPRISE\AvailabilityDatabases\AdventureWorks2012
This wraps up the AG cmdlets for the SQLPS module. As you can see, there is quite a bit of functionality here and pretty solid. I have some issues with the use of paths and lack of Get- commands, but overall there is good support here for automating the creation of Availability Groups. So much that they are a major part of my presentation at the 2015 SQL PASS Summit next week. If you’re there and would like to know more, check it out on Thursday (10/29) at 3:30PM.
Speaking of Summit, since I will be there this series will go on hold for a week. When I get back, we’ll wrap up with the handful of remaining cmdlets. Thanks for reading and we’ll see you back here on November 2.









 I’m tweeting!
I’m tweeting!