
Last year I joined on to Rubrik to help them sell their SQL Server database product. It’s been a fun challenge and definitely interesting working in the vendor space instead of having to field 3AM calls because something broke. This means that I talk to a lot of people about SQL backups and restores, especially about the challenges that your average data professional runs into. However, I based a lot of this conversation off of my anecdotal experience as a DBA. Being a data person, it felt a little awkward talking about these things in the absence of data.
This leads me to last week. In order to have some data, I decided to run an informal backup survey targeted at the SQL community. The results floored me: 344 of you decided to take my short survey. This really helps me understand some of the trends out there and now I want to share those results with you.
Before I get started, I want to first thank each and every person who responded from the bottom of my heart. This data is the result of your participation. Secondly, I want to underscore the “informal” nature of this. There’s a lot of holes that can probably be poked in the process, but I think the data is still useful and can give people insight into the trends.
I’ve posted raw data along with a few tools out on GitHub, where you are welcome to download and play with it. The tools include:
- Two SQL scripts that create and process the data into a simple data warehouse schema.
- An SSIS package (created by the SQL import wizard) that loads the raw data into the staging table
- A PowerBI report that has a couple basic charts built off of the data.
- A SQL 2016 SP1 backup of the database where I processed the .csv.
Note, my data warehousing/PowerBI skill set is nowhere as strong as others. I built something that was familiar to me and let me get at the data. I’m sure someone can build something better. Which is why I’ve made it public.
The Environment
As far as parsing out the data, let’s look at the questions and how people responded. The first questions were around how many SQL Servers(instances) and databases most people manage:
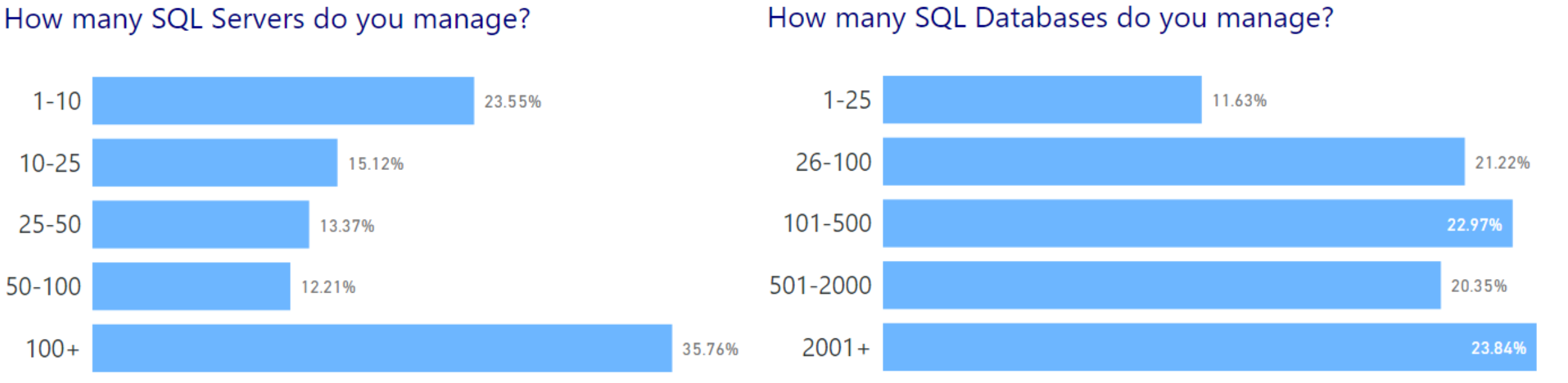
I think what’s interesting here is that the vast majority of folks out there manage a LOT of servers (36% have 100+ servers). Contrast this to a more balanced distribution across the database counts. This becomes even more interesting when contrasted against the data volumes:
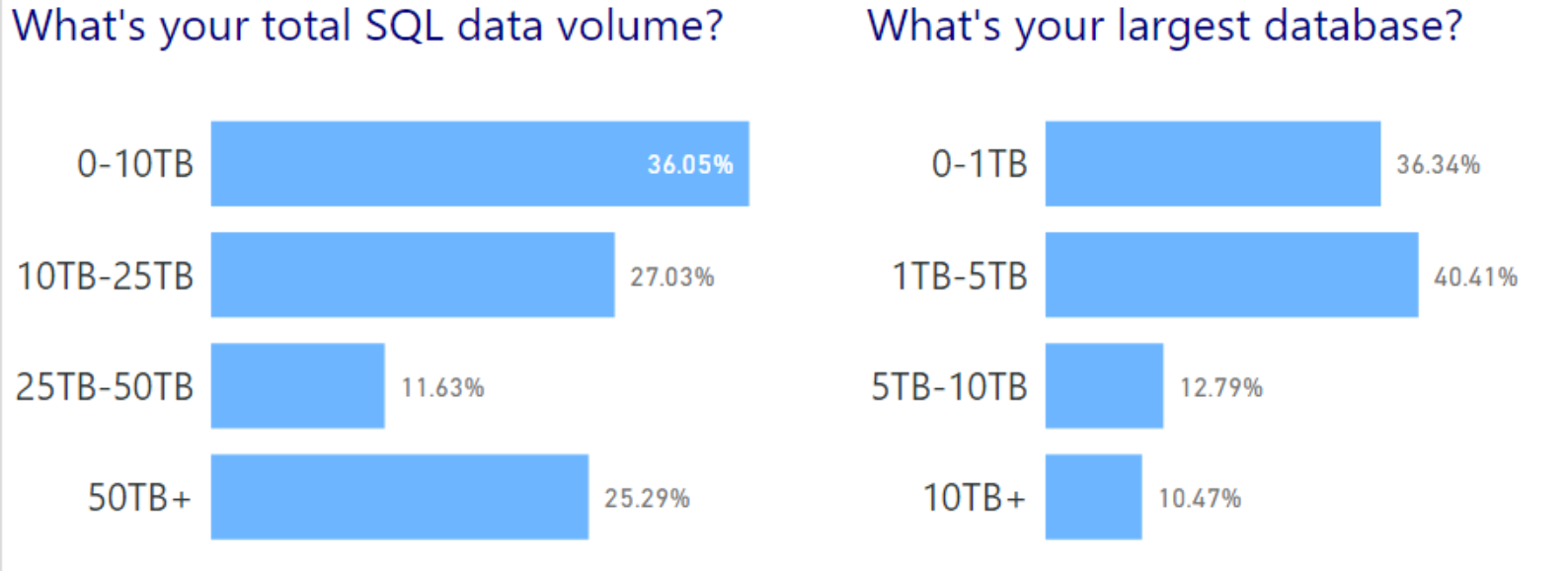
The majority of shops out there manage less than 25TB of total data, with most of these databases clocking in at 5TB or less. While 5TB is still a lot of data, this does mean that (when comparing this to the numbers above) most of the respondents manage “wide” environments, with more databases that are smaller in size. This becomes even more interesting when looking at the size of DBA teams:
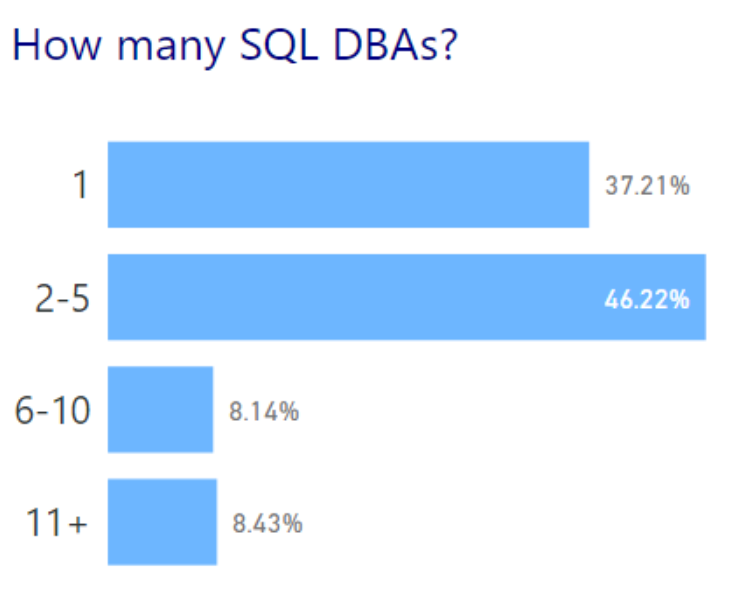
As you can see, the VAST majority (80%+) of companies employ teams of 5 DBAs or less. This means that in these wider environments, DBAs are responsible for a lot of objects. To me, this means that we have a lot of touchpoints to manage from a data protection standpoint.
SQL Use
Other interesting tidbits filter in with the questions on how SQL is used. Starting with just the versions of SQL in use, it’s not really surprising that Microsoft’s mainstream supported versions are in use out there:
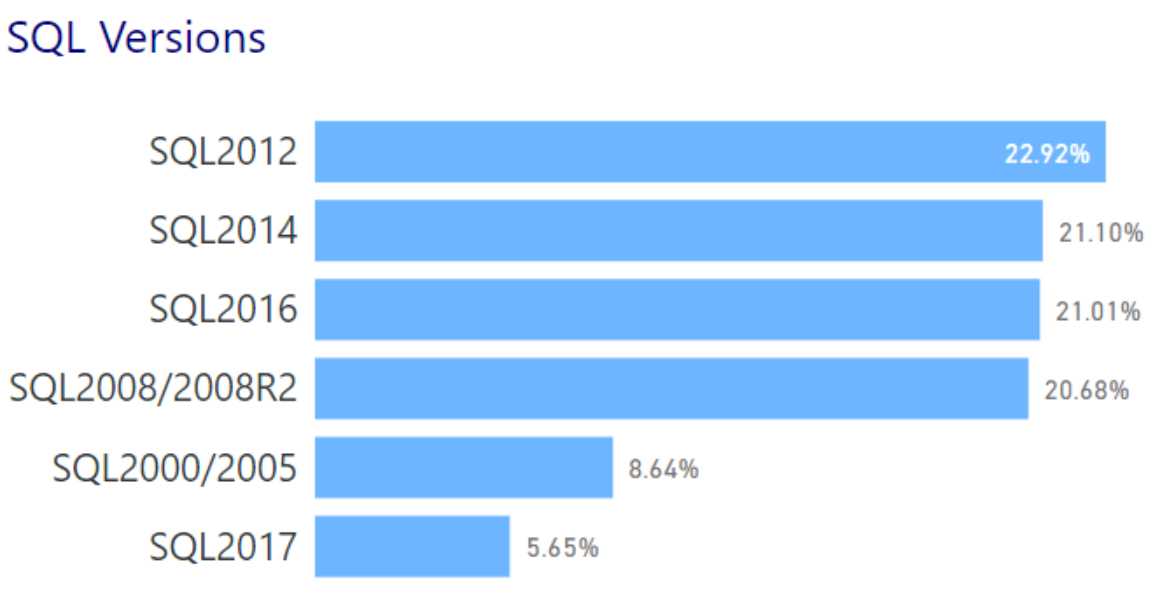
I was a little surprised at the SQL 2000/2005 number, but not shocked. I know how hard it is to phase out some of those legacy platforms.
Nothing really surprising when it comes to feature use either:
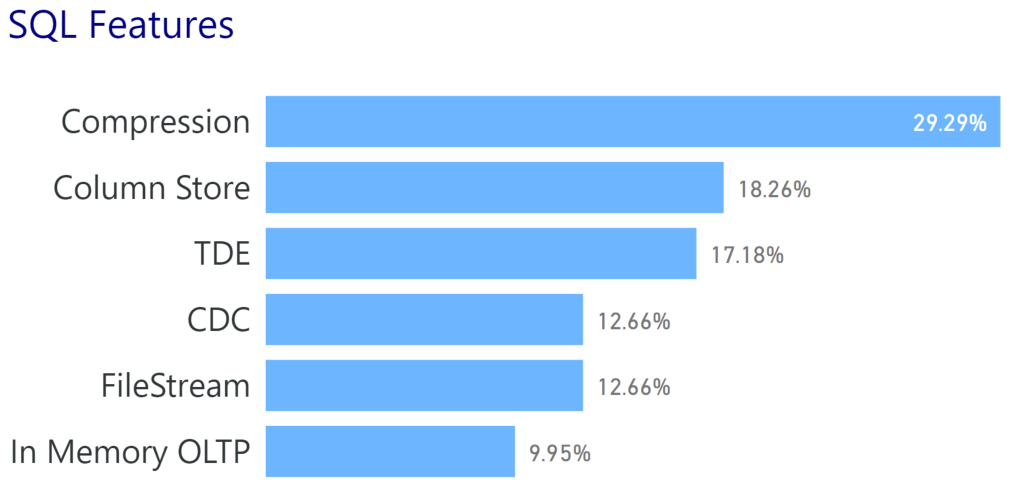
I did hope to see compression higher because of the performance impacts it has, but the rest of these values file in line with my expectations.
When it comes the High Availability/Disaster Recovery options, we also shouldn’t be too surprised:
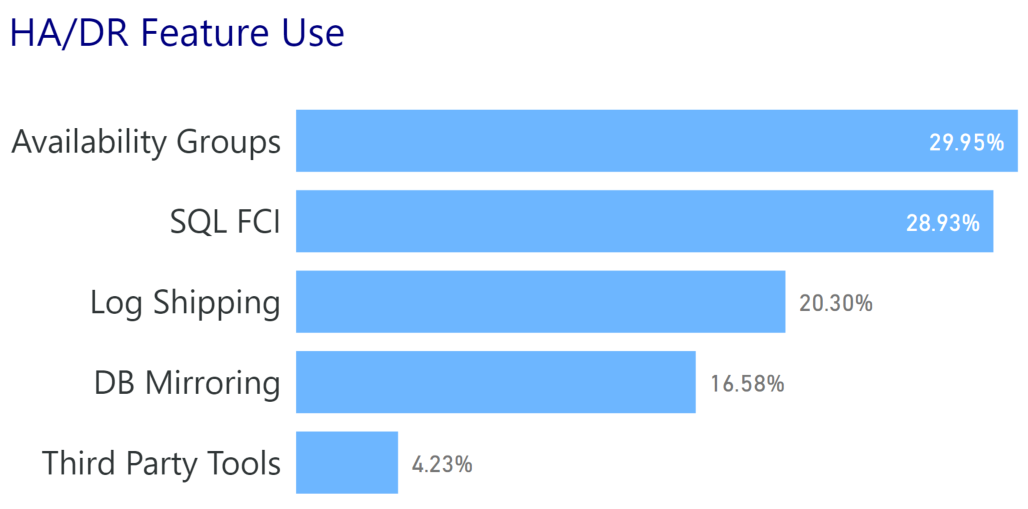
Availability Groups have been a strong offering from Microsoft and something they’ve marketed hard. This has resulted in solid adoption, but it’s only a little higher than Failover Cluster instances. I’m also not surprised by the Log Shipping use, because let’s be honest. It just works.
The final piece of data around backup tooling is of significant importance to me:
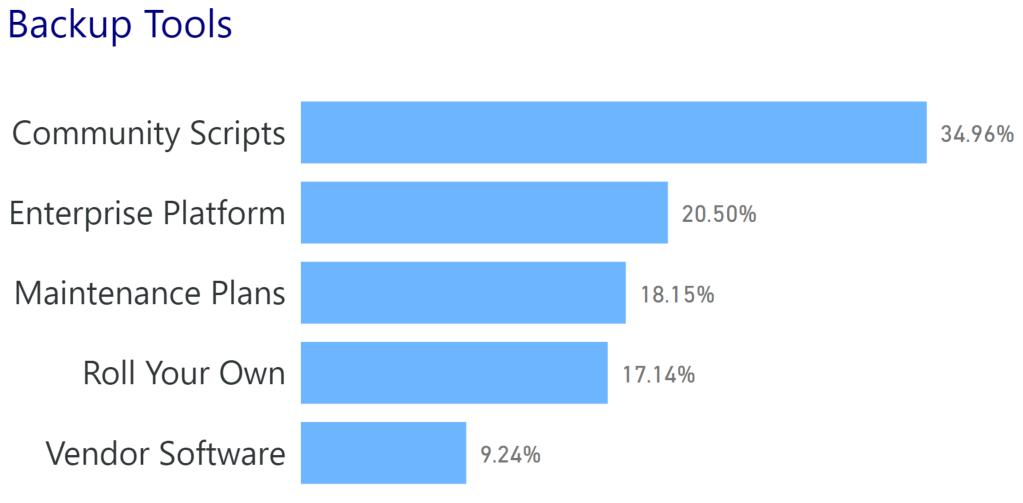
Almost 35% of you use some sort of community scripts, over 15% more than the next entry. This is significant because it means that most shops out there are relying on code that the SQL community provides for free. Think about that in context of other software platforms. Most are going to rely on purchased tools, but so many of us are comfortable with these community scripts that we entrust our company’s most important asset to them.
I was a little surprised at how high Enterprise Platform usage was, considering how many DBAs take a dim view of them. I think what also surprised me was that Vendor Software (Idera, Red Gate, etc.) was so low. Overall, we can definitely see where DBAs find value for running and managing their backups.
The Pain
The last question was more of a free form entry around what’s bugging people when managing backups. I’ll let folks browse it on their own, but here’s what I found interesting:
- ~21% of the responses referenced concerns about having enough space for their backups.
- Several respondents were frustrated by needing to build out reporting/management solutions.
- There were many concerns about having access to backups or being able to restore them in an emergency (mostly due to lack of space to either store enough backups or test them).
Wrapping It All Up
There’s probably a lot of different possible conclusions that can be leapt to from this data, certainly outside the ones I made. I’m certainly not claiming this survey as anything definitive, merely some interesting observations made from a healthy community response. Hopefully you also find the data interesting and I hope it sheds some light on to what’s happening out there in the wide world of SQL Server.
Before I go, a couple shout outs:
- Meagan Longoria (@mmarie) for telling me how and why my data visualizations sucked. Seriously, though, don’t hold what you find in the PowerBI report against her. :)
- Chris Lumnah (@clumnah) for helping me refine the survey questions.
- All the folks who shared the survey link, helping me get to 344 responses.
- The 344 of you who DID respond, helping make this survey into something worthwhile

 I’m tweeting!
I’m tweeting!