
 Welcome to the continuing blog party that is T-SQL Tuesday. This month’s host is Mickey Stuewe (@SQLMickey) with a challenge to blog about data modelling mistakes we’ve seen. Unfortunately, it’s an easy topic to blog about because proper data modelling often falls by the wayside in order to rapidly deliver applications. I’m not saying it should, but the fact of the matter is many developers are so focused on delivering functionality that they do not think about the long term implications of their design decisions.
Welcome to the continuing blog party that is T-SQL Tuesday. This month’s host is Mickey Stuewe (@SQLMickey) with a challenge to blog about data modelling mistakes we’ve seen. Unfortunately, it’s an easy topic to blog about because proper data modelling often falls by the wayside in order to rapidly deliver applications. I’m not saying it should, but the fact of the matter is many developers are so focused on delivering functionality that they do not think about the long term implications of their design decisions.
One such mistake is the selection of Globally Unique Identifiers (GUIDs) for a data type. Developers love this data type for a lot of reasons, some of them very good. The fact that GUIDs are globally unique provides a way to keep data unique when migrating along with a nicely obfuscated surrogate key that can help protect user data. All in all, I can not really blame people for wanting to use this data type, but the problem is that SQL Server does not manage that data type very well behind the scenes.
The problems with GUIDs in SQL Server are fairly well documented. As a quick review for context, the issue is that since GUIDs are random values, it is hard to efficiently index them and these will rapidly fragment. This means slower inserts and more disk space taken up by the index. I created the following two tables (one with a GUID, one with an INT) and inserted 2000 rows into each:
create table GUIDTest(
orgid uniqueidentifier default NEWID()
,orgname varchar(20)
,CONSTRAINT pk_GUIDTest PRIMARY KEY CLUSTERED (orgid));
create table NonGUIDTest(
orgid int default NEXT VALUE FOR NonGuidSeq
,orgname varchar(20)
,CONSTRAINT pk_NonGUIDTest PRIMARY KEY CLUSTERED (orgid));
The results from sys.dm_db_index_physical stats tell the story from a fragmentation and size perspective:

So GUIDs are bad. With as much as has been written on this topic, it feels a bit like shooting fish in a barrell. However, GUIDs will find their way into databases because of their usefulness to the application layer. What I want to talk about is a common misconception around “solving” the GUID problem: clustering on a sequence ID but keeping the GUID in the table.
Let’s start by creating a new table to have a GUID and cluster on a sequence:
create table SeqGUIDTest(
seqid int default NEXT VALUE FOR GuidSeq
,orgid uniqueidentifier default NEWID()
,orgname varchar(20)
,CONSTRAINT pk_SeqGUIDTest PRIMARY KEY CLUSTERED (seqid));
 As expected, less fragmentation and size. This is good, right? It can be, but here’s the problem: the sequence is completely meaningless to our data and our queries will likely not use it (unless we build in additional surrogate abstraction to relate sequence to our GUID). Let’s compare query plans for our GUIDTest and SeqGuidTest tables where we query each for a specific orgid value:
As expected, less fragmentation and size. This is good, right? It can be, but here’s the problem: the sequence is completely meaningless to our data and our queries will likely not use it (unless we build in additional surrogate abstraction to relate sequence to our GUID). Let’s compare query plans for our GUIDTest and SeqGuidTest tables where we query each for a specific orgid value:
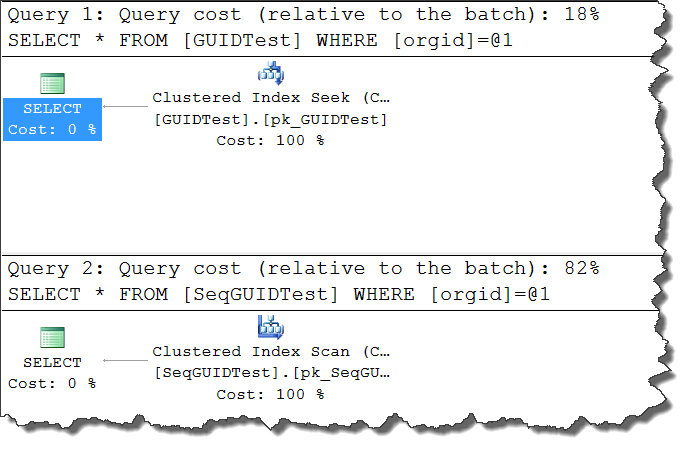
The query where the GUID is a clustered index is far more efficient than the one against the table where we cluster on a sequence. This is because it can leverage the index, meaning we will get a seek instead of a scan. While clustering on a sequence field saves us on space and fragmentation, it ends up hurting us when trying to do data retrieval.
If we were tuning the query against SeqGuidTest, the next logical step for tuning would be to create a non-clustered index on orgid. This would improve the query, but in order to make it useful (and avoid key lookups), we would need to include all the columns of the table. With that, we have completely negated any benefit we got from clustering on a sequence column, because the situation is now:
- A clustered index that is the table, thus using all that disk space.
- A non-clustered index that also uses as much space as the table (it has all the columns in it as well).
- The non-clustered index now has the same fragmentation problem we were trying to avoid on the clustered index.
So while trying to avoid a problem, we have made the problem worse.
There are two lessons here. The first is the classic “it depends” case. There are no hard and fast rules to how we implement our databases. You need to be flexible in creating your design and understand the complete impact of your choices. Clustering on a GUID is not great, but in the above case it is far better than the alternative.
The second lesson is to understand your data and how it is going to be used. When we build tables and indexes, we need to be conscious of how our data will be queried and design appropriately. If we use abstractions like surrogate keys, then we need to make sure the design is built around that abstraction. In the above examples, we could cluster on a sequence key, but only if that sequence key has some sort of meaning in our larger database design. Building a better database is about understanding our relationships and appropriately modeling around them.
Thanks to Mickey for the great T-SQL Tuesday topic! Please check her blog for other great posts throughout the day.

 I’m tweeting!
I’m tweeting!