
 Businesses have always struggled with the high cost of relational database servers, both from a hardware and licensing perspective, because current RDBMS platforms take the approach that you will have one or two powerhouse servers handling your data workload. While this has been the commonly accepted practice, the evolution of the cloud and better distributed computing architectures have given rise to new approaches for data storage and processing. Now businesses are rethinking their approach to infrastructure with these new approaches, finding ways to provide better performance and higher availability all at a lower price point.
Businesses have always struggled with the high cost of relational database servers, both from a hardware and licensing perspective, because current RDBMS platforms take the approach that you will have one or two powerhouse servers handling your data workload. While this has been the commonly accepted practice, the evolution of the cloud and better distributed computing architectures have given rise to new approaches for data storage and processing. Now businesses are rethinking their approach to infrastructure with these new approaches, finding ways to provide better performance and higher availability all at a lower price point.
Non-relational data stores embrace this new approach with how they cluster. Designed in response to the single, super-pricey database server, non-relational systems take the approach of clustering many inexpensive servers into one database. This is sold as having many advantages to businesses, such as:
-
Horizontal scalability, allowing business to better adapt to growing workloads. Need more power? Just add another commodity hardware server, you’re not trapped by the box you bought last year.
-
Distributed data across many machines, making the database more available and increasing the durability against failure. Think of it as RAID for your data, so that if one box goes down, the system is still up and you just need to replace the one failed box.
-
Costs are lower and more manageable. Well, at least more manageable, where you can buy only the computing power you need and grow incrementally over time. However, there’s a lot of factors (from virtualization to overall hardware costs) that make the total price point versus a beefy relational server fairly comparable.
It’s certainly a departure from how we’ve dealt with relational platforms to date (though I’m super intrigued by Google’s F1 database). There are some definite advantages, but most tech people look at this and say “Well, that sounds fancy, but does it blend?” And by blend, we mean work. The answer has actually been around for some time now and many large businesses already use it in their relational databases: partitioning.
 Partitioning is a concept we’ve had in the relational world for some time now (and feel free to look at my partitioning posts for more info). Even before the major RDBMS platforms introduced their own partitioning functionality, DBAs would partition data out into different tables and bring them together as a view (commonly known as partitioned views). What the non-relational folks do is take it a step further, saying that instead of just partitioning your data across different disks, why not distribute it across different computers? By doing that, businesses not only get to spread the workload across all these computers, but their data availability is no longer dependent on a single OS/application instance.
Partitioning is a concept we’ve had in the relational world for some time now (and feel free to look at my partitioning posts for more info). Even before the major RDBMS platforms introduced their own partitioning functionality, DBAs would partition data out into different tables and bring them together as a view (commonly known as partitioned views). What the non-relational folks do is take it a step further, saying that instead of just partitioning your data across different disks, why not distribute it across different computers? By doing that, businesses not only get to spread the workload across all these computers, but their data availability is no longer dependent on a single OS/application instance.
Of course, what this means is that non-relational data stores still need some way to determine how data is partitioned. Remember last week when I talked about all non-relational stores being key/value stores? Well, those keys become even more important because they become the partitioning key (also called a shard key, by some), the value that non-relational platforms use to divvy up the data between its partitions. Now, most of these datastores will analyze the key values and attempt to balance that data as evenly as possible, but it’s something you need to be aware of when modelling out your data. A poorly chosen partition key could mean you’re negating your cluster advantage because your data will end up in one or two nodes. We’ll come back to this in a bit.
At this point we should talk a bit about the CAP Theorem. This bit of computer science was introduced back in 2000 and conceptually defines the limitations of a distributed computing system. The gist of it is that, while we’re trying to accomplish all these wonderful things, any clustered platform cannot guarantee:
-
Consistency (That all the data on all the nodes is the same)
-
Available (That all the data is the same on all the nodes)
-
Partition Tolerant (That the application will remain up despite the loss of one of its partitions)
Commonly, you’ll hear people say that you can only have two out of these three things at any time. What this means to non-relational platforms is that, since they’re all designed to be partition tolerant with their clustered nodes, we have to chose between being consistent or available.
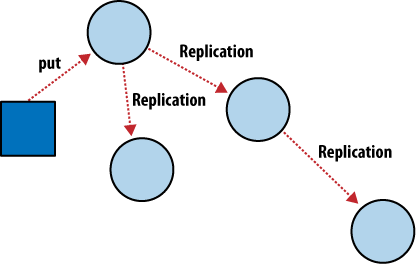 This is where eventual consistency comes in to play. See, the problem with our clusters is that we still have the laws of physics involved. When data is written and that data is distributed across multiple nodes, then there is a matter of time where data has to be communicated across a network and written to disks in different computers. Most non-relational systems take the availability path here, meaning that data will be offered up from the various nodes, even if it’s not all up to date. The idea is that it will be eventually consistent, but you might have to wait a bit.
This is where eventual consistency comes in to play. See, the problem with our clusters is that we still have the laws of physics involved. When data is written and that data is distributed across multiple nodes, then there is a matter of time where data has to be communicated across a network and written to disks in different computers. Most non-relational systems take the availability path here, meaning that data will be offered up from the various nodes, even if it’s not all up to date. The idea is that it will be eventually consistent, but you might have to wait a bit.
Now our relational brains might kick back on us. “Shouldn’t our data be 100% accurate all the time!?!?” ACID compliance, right? It depends! Once again, we have to ask ourselves what data is being stored in our database. Much of this detail only needs to be accurate at a point in time within an application, once it gets into the database we have a little more time before we have to deal with it. If not, you might consider using a relational database for your data. It’s all about using the right tool for the job.
One big concern coming out of this distributed model is the question of backups. Non-relational folks will tell you that backups for disaster recovery aren’t really necessary because you have it built in. However, most DBAs I know (and I’m one of them) will tell you that disaster recovery and high availability are not the same thing. And because of the distributed nature, backups become really complex. So you have to ask yourself when designing or implementing one of these solutions, how will you handle this? In some cases, it might be a simple matter of backing up the files, but my research so far has shown that this requires an operating system file lock in order to keep things consistent. Which means you stop your application (i.e., no hot database backups). There might be other alternatives, either available or in development (the vendors of these platforms recognize the gap), but be aware that it will be a question you have to address.
The key takeaway for this post is that the distributed nature of non-relational systems is a huge advantage for them, but it has some hurdles to overcome. It’s simply not a magic bullet to all your data problems. Again, the theme here is using the appropriate tools for the appropriate purposes. Recognizing the strengths and weakness is key to knowing when you should use a tool and, because NoSQL is a hot trend, it’s vital to understand it in order to properly guide your company’s conversations around the technology.
Next up, I want to talk about how non-relational systems leverage this dispersed architecture for querying and analyzing data. It’s a strong offering, but not always fully understood. Hopefully these last two posts are getting you interested in this realm of data management, but remember I’m only touching the surface here. NoSQL is as deep (though not nearly as mature) as the RDBMS world and there’s a lot more learning than I can provide here.



 I’m tweeting!
I’m tweeting!