
I’ll be the first to tell you I’m not a fan of extended events. The why is a whole other blog post unto itself, but since T-SQL Tuesday is all about learning, I figured I’d take a stab at things. Furthermore, since I like to talk about Powershell, it seems like a good opportunity to explore a little about how we can manage extended events through that language.
The SQLPS Provider
The simplest entry point into interfacing with SQL Server is the SQLPS provider. Yes, I know there’s a lot of gripes about it (and that’s yet ANOTHER blog post I’m working on). However, it’s still a good starting point. To load up the provider is easy:
Import-Module SQLPS
Providers in Powershell are nice because we get to interact with different parts of the stack as if they were file systems. When you load up the provider, you’ll get a SQLSERVER drive that you can do a directory lookup on.
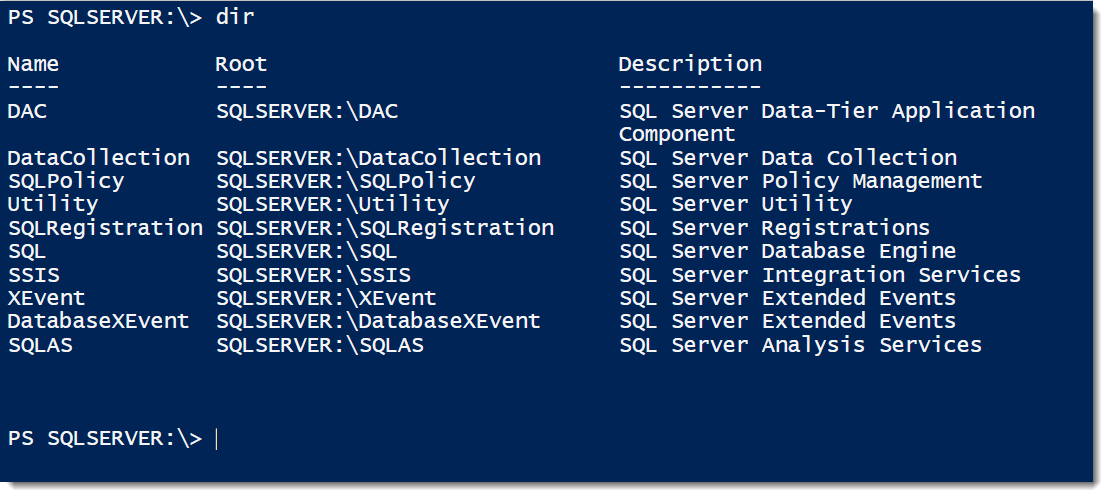
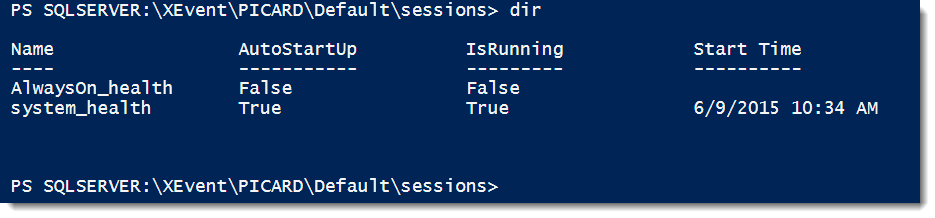
 Notice how we have an XEvent folder? This is how we can start exploring our extended events. The format for the lookups is the standard format. If we drill down, we start to see lookups that match what we see in Management Studio. Looking at SQLSERVER:\XEvent\PICARD\Default\sessions will give us a quick listing of all the sessions on that instance and if they’re running or not.
Notice how we have an XEvent folder? This is how we can start exploring our extended events. The format for the lookups is the standard format. If we drill down, we start to see lookups that match what we see in Management Studio. Looking at SQLSERVER:\XEvent\PICARD\Default\sessions will give us a quick listing of all the sessions on that instance and if they’re running or not.
Thinking Objectively
As we further explore this, we need to remember that everything in Powershell is an object. This specifically means that with the SQLPS provider, everything is an SMO object. By leveraging the trusted Get-Member cmdlet, we can quickly find out that we are dealing with Microsoft.SqlServer.Management.XEvent objects and the Session class. So what can we do with this?
First off, I found a bit of a gotcha when trying to assign these sessions to objects in Powershell. Normally, I’d just use Get-ChildItem on the name to populate the variable, but when I tried to do that I ended up with a string object. Not very useful. In order to get the proper assignment, I had to work around it a bit and ended up with this:
$xe = dir | Where-Object {$_.name -eq 'system_health'}
$xe | gm
Why this is different from the usual ‘dir system_health’ is unknown, but is the result of how the SQL Server team implemented the provider (yes, another post for another time). However, now we have an object and can start leveraging some of the properties. Here’s a couple examples of some of what you can look at:
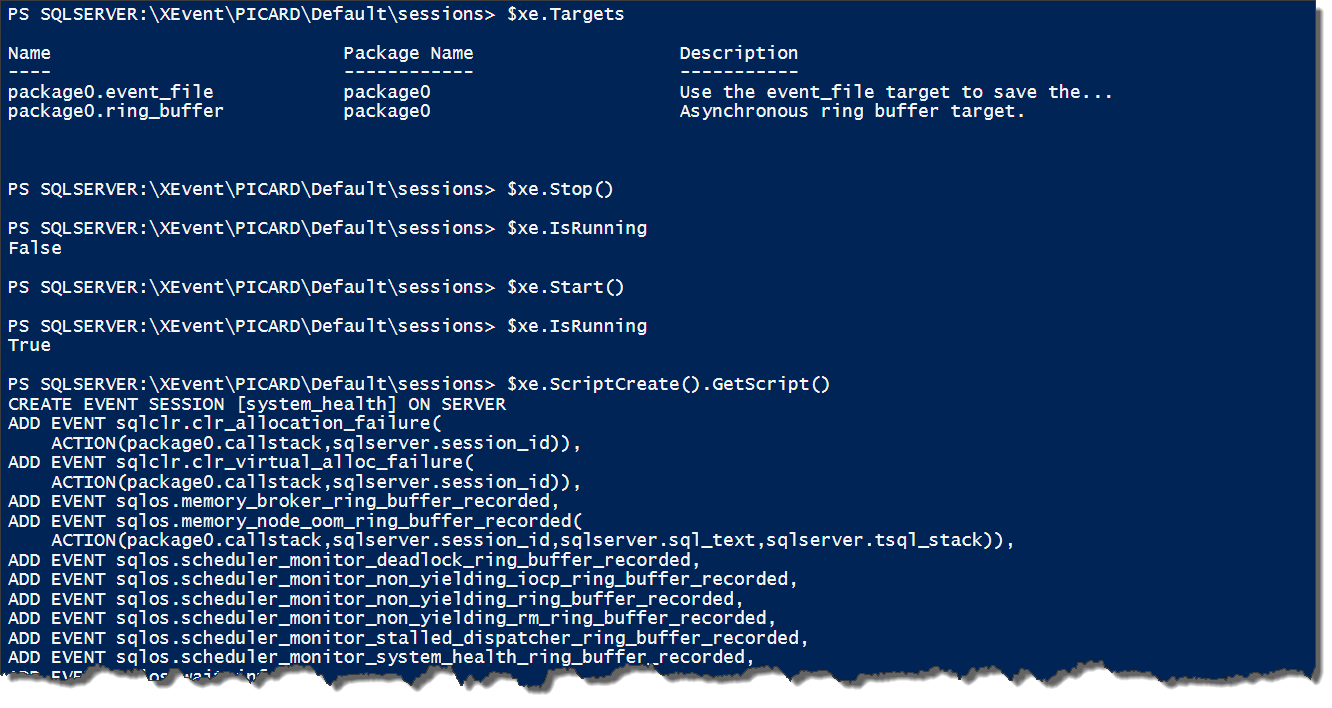 The calls I used for the above are:
The calls I used for the above are:
$xe.Targets $xe.Stop() $xe.IsRunning $xe.Start() $xe.IsRunning $xe.ScriptCreate().GetScript()
You’ll notice at least one funky bit of syntax here around scripting. While most SMO objects give you a .Script() method, these objects require you to first call a .ScriptCreate() (or alter or drop) method, which returns an ISfcScript script object. You then have to call that object’s .GetScript() method to actually generate your script. It’s a little bit of a long way around the horn, but you get there.
Practical Application
What can we do with this? I’ll be the first to admit that some of this is clunky, but much of that is probably my general unfamiliarity with this aspect of the provider and extended events in general. However, I can definitely start to see some specific use cases, such as:
- Backing up existing custom sessions across my environment by scripting them out with a scheduled job.
- Checking that all system_health sessions on my SQL Servers are running.
- Executing a mass change to my extended events sessions using the methods.
To effectively leverage Powershell with extended events, we need to play to the language’s strengths. The focus here is on multi-server execution and scripting for consistency. This is also just a start. As you (and I) continue to explore this facet of the SQL Server provider, many other use cases and situations may show up.
Thanks out to Jes Borland(@grrl_geek) for hosting this month’s T-SQL Tuesday. Remember to watch the #tsql2sday tag for other great blog posts.






 I’m tweeting!
I’m tweeting!