SQL Server backups are a key part of any database administrator’s job and one of the first items that will get automated in an environment. In my career, I have seen a number of different approaches to this task, usually a combination of T-SQL and SQL Agent Jobs. When using these, you usually have two different approaches. The first is to create a single script to dynamically identify your databases and back them up serially. The second is to create multiple agent jobs, one for each database, that can execute in parallel, but must be created as static jobs.
Either approach presents us with some hurdles. The first enables us to dynamically handle adding databases to the server, but the backups must be executed serially. Serial backups can extend maintenance windows by not making efficient use of our resources. The second gives us the ability to run our backups in parallel, but leaves us with multiple jobs that are static and must be managed as new databases are added. Neither of these options are really ideal.
What if there was a third way?
Enter Powershell Jobs. While I usually don’t advocate database backups using Powershell (because they can be handled quite well with native T-SQL), I have come across a handy technique using Powershell Jobs and T-SQL to allow me to dynamically create backup statements and execute them in parallel. This allows me to find that intersection between minimal management and increased efficiency for my database backup management.
So what are Powershell Jobs? They are a mechanism within Powershell for creating background jobs that can execute independent of the session that initiates them. Using this functionality, we can start multiple executions of any Powershell command in parallel, allowing them to run while other tasks execute. To find out more, you can read the documentation by running Get-Help about_Jobs or look them up on MSDN.
Start-Job is the key to this technique. To implement, I first use T-SQL code to get my databases for backup, much like I would when using pure T-SQL. Using this T-SQL, I will create an array of databases to be backed up and use that array to build a script block. This script block will contain a call to Invoke-SqlCmd for each backup statement, which can then be used with Start-Job to execute each backup job.
$dbs = Invoke-Sqlcmd -ServerInstance localhost -Database tempdb -Query "SELECT name FROM sys.databases WHERE database_id > 4"
$datestring = (Get-Date -Format 'yyyyMMddHHmm')
foreach($db in $dbs.name){
$dir = "C:\Backups\$db"
if(!(Test-Path $dir)){New-Item -ItemType Directory -path $dir}
$filename = "$db-$datestring.bak"
$backup=Join-Path -Path $dir -ChildPath $filename
$sql = "BACKUP DATABASE $db TO DISK = N'$backup'"
$cmd = "Invoke-Sqlcmd -ServerInstance localhost -Database tempdb -Query `"$sql`" -QueryTimeout 6000;"
$cmd += "Get-ChildItem $dir\*.bak| Where {`$_.LastWriteTime -lt (Get-Date).AddMinutes(-10)}|Remove-Item;"
[scriptblock]$cmdblock = [ScriptBlock]::Create($cmd)
Start-Job $cmdblock
}
In addition to using Powershell to create jobs, we also get some bonus features. For example, I can use Test-Path to validate my backup directories exist (and create them if they don’t).
(!(Test-Path $dir)){New-Item -ItemType Directory -path $dir}
Backup paths are big deal for SQL Server, because if that path doesn’t exist, we get an ugly backup error. When using a T-SQL script for backups, administrators still need some additional step to create the backup directories. This is a task that is much easier using Powershell.
We can also leverage Powershell for deleting old backups by adding the following line:
$cmd += "Get-ChildItem $dir\*.bak| Where {`$_.LastWriteTime -lt (Get-Date).AddMinutes(-10)}|Remove-Item;"
Deleting files is something SQL Server is also particularly bad at. I’ve had a lot of sleepless nights that were the result of old backup files not being cleaned up. By leveraging this one line in the script block, the job will delete any full backups older than 10 minutes. We could change this window or be more elegant as our needs require, but the end result is that we only keep the most recent backup file.
What’s nice is that the script can be easily extended for log backups without a lot of retrofitting. I make four changes for this. The first is to filter our database query to ignore any databases in SIMPLE mode, as they can’t have their log files backed up.
$dbs = Invoke-Sqlcmd -ServerInstance localhost -Database tempdb -Query "SELECT name FROM sys.databases WHERE database_id > 4 AND recovery_model_desc != 'SIMPLE'"
The second is change the backup command from BACKUP DATABASE to BACKUP LOG.
$sql = "BACKUP LOG $db TO DISK = N'$backup'"
Next, I change the backup file extension from .bak to .trn, because I prefer to distinguish my backup file types in this manner.
$filename = "$db-$datestring.trn"
Finally I change the retention period for the delete step to 2 days, so I can keep transaction logs on disk in the event I need them for recovery.
$cmd += "Get-ChildItem $dir\*.trn| Where {`$_.LastWriteTime -lt (Get-Date).AddDays(-2)}|Remove-Item;"
The end result is this script, which works much like our full backup script:
The end result is this script, which works much like our full backup script:
$dbs = Invoke-Sqlcmd -ServerInstance localhost -Database tempdb -Query "SELECT name FROM sys.databases WHERE database_id > 4 AND recovery_model_desc != 'SIMPLE'"
$datestring = (Get-Date -Format 'yyyyMMddHHmm')
foreach($db in $dbs.name){
$dir = "C:\Backups\$db"
if(!(Test-Path $dir)){New-Item -ItemType Directory -path $dir}
$filename = "$db-$datestring.trn"
$backup=Join-Path -Path $dir -ChildPath $filename
$sql = "BACKUP LOG $db TO DISK = N'$backup'"
$cmd = "Invoke-Sqlcmd -ServerInstance localhost -Database tempdb -Query `"$sql`" -QueryTimeout 6000;"
$cmd += "Get-ChildItem $dir\*.trn| Where {`$_.LastWriteTime -lt (Get-Date).AddDays(-2)}|Remove-Item;"
[scriptblock]$cmdblock = [ScriptBlock]::Create($cmd)
Start-Job $cmdblock
}
So how do we use this in SQL Server? We can stick with the previous pattern of using SQL Server Agent Jobs. Since SQL Server 2008, Agent Jobs have supported a Powershell step. To implement that step, we would create our same backup job in the Agent as before, but now instead of creating a T-SQL step we can create a Powershell step and insert our script, like so:
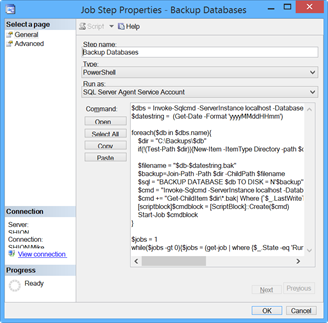
There is one additional piece of code we have to add to make it work, however. The way Agent Jobs operate is that once the script completes and our background jobs are initiated, the Agent Job step stops and closes our parent session. When this happens, the remote jobs we just kicked off get canceled and our backups don’t happen. We need to add a logic check to keep the Agent Job running until the background jobs are no longer running. This is simple and only requires the following code to accomplish our task:
$jobs = 1
while($jobs -gt 0){$jobs = (get-job | where {$_.State -eq 'Running'} | Measure-Object).Count}
With this in place, we can now schedule and run our backup task as we would have before, except now we have a more dynamic and more efficient Powershell script to do it with. We can also do the same with our log backup script as well.
Overall these are very basic scripts and could be enhanced, but the core functionality is what you should focus on. The emphasis is on making the best use of our tools and resources in the most efficient way possible. This approach is also nice for SQL Server administrators as the script is primarily a wrapper for T-SQL backup commands that we all know and love. For those SQL Server folks who are still getting their feet wet with Powershell, this is a very intuitive way to start using the syntax and get some quick bang-for-your-buck.








 I’m tweeting!
I’m tweeting!