As a DBA, I’m always concerned with consistency in my environments. From maintenance to code deploy, I want things to be done the same way every single time. Usually this is a process question, making sure that you harness the power of check lists and repeatable steps. You then make it better by wrapping your process in scripts and leveraging other tools.
When I go into a new shop, one of the first things I usually have to do is bolt down the server build process. Most environments will manually build servers, where an engineer goes in and manually installs the appropriate packages and features. Then a DBA will install SQL Server, adding maintenance jobs and deploying admin databases. Even with building scripts and sketching out steps, there will be a lot of spots where configurations can be missed and the process can breakdown. Fortunately, we now have a tool in Powershell that helps us solve these problems.
You might have heard of Chef or Puppet. Well, now Powershell has its own answer for managing server configurations: Deired State Configuration or DSC. DSC is an engine included in Windows Management Framework 4 that allows folks like us to create declarative configurations for our servers which can then be acted on by our servers. This brings the next level of automation, infrastructure as code, to our servers.
How does it work?
The process for DSC relies on two things: Your configuration and your resources. You create a configuration, which specifies the resources you want (or don’t want). You then use DSC via Powershell to deploy the configuration to a target server, which then runs the configuration through a Local Configuration Manager (LCM) to check those resources. If those resources are present, the LCM takes note and moves on. If the resources is not present as declared in the configuration, the LCM will then attempt to install or configure the resource as specified in the configuration file.

Simple, eh? It’s meant to be that way. The idea is to have an intuitive way to deploy servers in a standardized method, whether it’s 1 or 100 (or 1000 for that matter). It’s also meant to be flexible. DSC ships with some basic resources (things like File, Windows Feature, and Registry Key), but because it’s built in Powershell you have the ability to create your own resources. This means the sky’s the limit with what you can do.
What do I need?
Let’s dig a little more into the detail of how DSC works. First off, if we want to use DSC, we need a couple things:
- Windows Management Framework 4.0 on all machines involved
- Permissions to run custom scripts on the targets (if we’re using custom resources, more on this later)
- Custom resources need to be deployed to the target ahead of deploying the configuration
Note I call out some requirements around custom resources. These are scripts you write yourself. We’ll talk about those in a bit, just file these bits away for later reference.
Now, the configuration. This is a configuration I created for deploying a base installation of SQL Server, so the resources are designed around that. Here’s the script:
Configuration SQLServer{
param([string[]] $ComputerName)
Import-DscResource -Module cSQLResources
Node $ComputerName {
File DataDir{
DestinationPath = 'C:\DBFiles\Data'
Type = 'Directory'
Ensure = 'Present'
}
File LogDir{
DestinationPath = 'C:\DBFiles\Log'
Type = 'Directory'
Ensure = 'Present'
}
File TempDBDir{
DestinationPath = 'C:\DBFiles\TempDB'
Type = 'Directory'
Ensure = 'Present'
}
WindowsFeature NETCore{
Name = 'NET-Framework-Core'
Ensure = 'Present'
IncludeAllSubFeature = $true
Source = 'D:\sources\sxs'
}
cSQLInstall SQLInstall{
InstanceName = 'MSSQLSERVER'
InstallPath = '\\HIKARU\InstallFiles\SQL2014'
ConfigPath = '\\HIKARU\InstallFiles\SQL2014\SQL2014_Core_DSC.ini'
UpdateEnabled = $true
UpdatePath = '\\HIKARU\InstallFiles\SQL2014\Updates'
DependsOn = @("[File]DataDir","[File]LogDir","[File]TempDBDir","[WindowsFeature]NETCore")
}
}
}
SQLServer -ComputerName MISA
This looks like (and is) a Powershell function, just a special one using the ‘Configuration’ key word. When you call the function, it will create a special file for the Node(s) declared within the configuration, a Managed Object Format (.mof) file. This is a standardized file type that defines our configuration. Note, this file is not Windows specific, as the design for DSC is to ultimately be used with non-Windows OS machines and hardware. It’s the .mof that will be deployed to our target machines and acted upon by the LCM.
Next up in the file, the Node. This is the target for our configuration. You’ll see that in the script, it is parameterized as an array, meaning we can run the script for as many different targets as we want, we just have to pass the array of machine names we want. We could also have multiple nodes within the configuration script, if we wanted this configuration to have different types of targets.
Within the Node section, we have our resource declarations. This is the meat, the pieces of code that identify what needs to be configured. The nice thing is reading them is fairly intuitive. Let’s look first at the File resource. These three declarations are for my default directories. I have to declare specify that it is a directory (the Type), the path (the DestinationPath), and that is must exist (Ensure = Present). As an aside, I could get a lot more involved with the File resource, copying things from a net share down to the target if I wanted, things like config files or web source directories.
The Windows Feature resource is also easy to understand. Using this, I can make sure certain Windows features exist on the target. Since I’m using this particular configuration to install SQL Server, I’ve declared that I want the Net-Framework-Core feature installed. This is a prerequisite for installing SQL Server.
Finally, I have the cSQLInstall resource. I’m going to save the explanation of this detailed custom resource for the next blog post, but I want to call attention to the DependsOn argument. With this, we can declare prerequisites for our resources. This give us some additional resilience for our install, allowing us to create some precedence within the configuration.
Where do I run it from?
Once you have the configuration written, you simply need to run it. It will create a directory named after your configuration and contain a .mof file for each node within it. The next step is to use the Start-DscConfiguration cmdlet and call the path where all our files live. After that, a Powershell background job kicks off and DSC handles the rest.
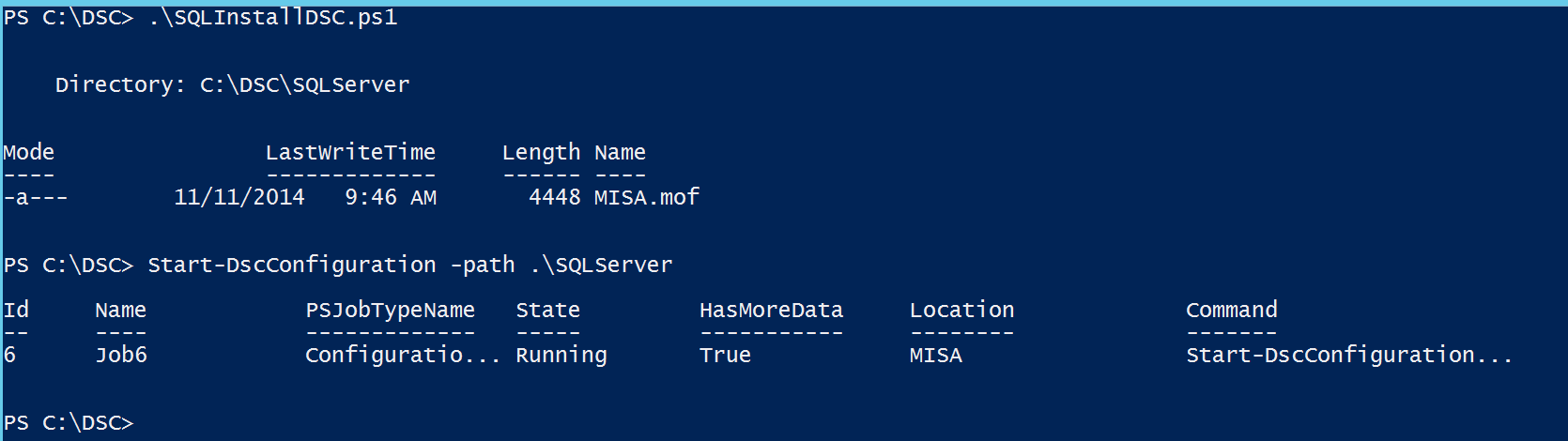
Any not cool parts?
So not everything is unicorns and rainbows with DSC. First off, it’s a stone cold female canine to debug, because it’s difficult to capture any logging around it. Many times I would try and run something and it would fail before it even entered my script. Most of this was around my custom stuff, but it was extremely frustrating.
As for the custom scripts, DSC is still fairly immature. Microsoft has some resource kits out there, but most of the resources in there are pretty weak. The SQL resource provided has several gaps, such as being designed specifically for SQL 2012 and not being able to use .ini files. So you’re probably going to write resources on your own, which has a LOT of gotchas. You’re going to want to start with the Resource Designer Tool, which will solve most of the gotchas for you.
Also, since it’s immature, there’s not a lot written about it. Especially for SQL Server. Powershell.org and MSDN are going to be your best bets for help, but this is a brave new world. Be prepared to walk a fair amount of the way on your own. If you want to start, go with this book from Don Jones.
Infrastructure as code is the future. DSC gives us intuitive tools with a straightforward interface (once your resources are written, of course) to make our environments more consistent and easier to manage. I’m super excited about this feature and will be blogging more about it in the weeks to come. Definitely stay tuned for next week, where I’ll walk through my custom SQL Server resource (and tell you where you can get the code yourself). Also, hit me up if you’ve got questions or any experiences of your own around DSC, I’d love to hear about them.



 I’m tweeting!
I’m tweeting!