
For those not aware, I’ve been selected as a presenter at this year’s PASS Summit in Charlotte, NC. I’m deeply honored by the selection and look forward to the experience. The topic is something I’ve been working on for sometime now: How should administrators approach monitoring? This seems like a simple question, but go Bingle “SQL Server Monitoring” and see what you get. Go ahead, I’ll wait.
The results are either tools or metrics. While these are useful, it highlights a significant gap out there: a methodology. The closest you’ll find out there is Adam Machanic’s (@adammachanic) Ten Commandments Of SQL Server Monitoring (which applies to all monitoring, really, but I digress). The goal with my PASS presentation is to provide a “how to” plan for creating your overall monitoring strategy.
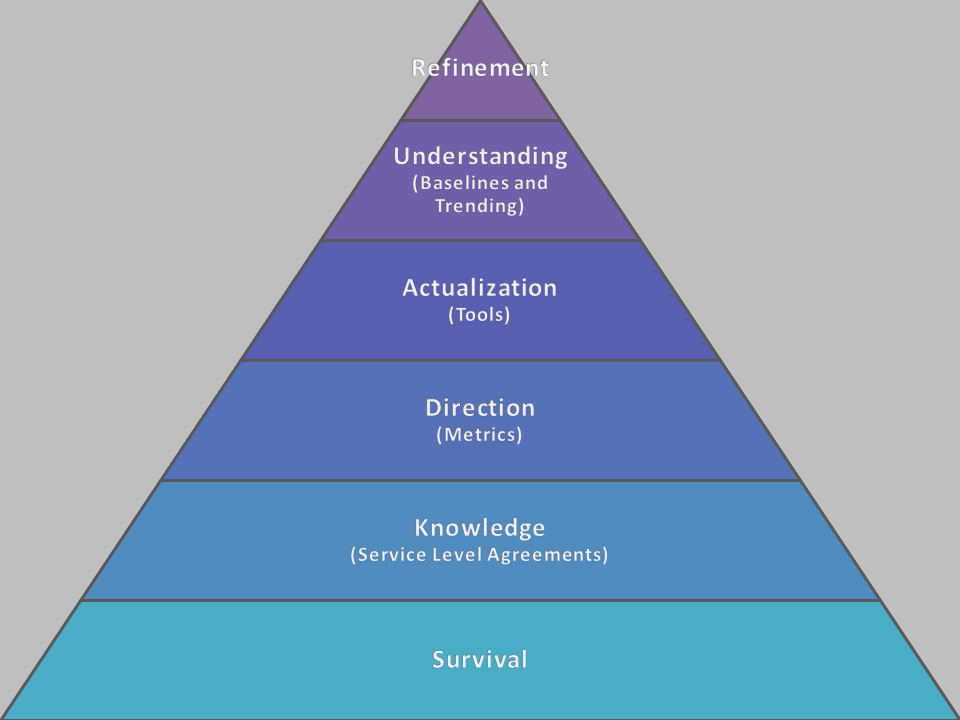
How does this methodology work? Several years ago I was introduced to Maslow’s Hierarchy of Needs. It’s a structured view of what humans need, built around a tiered view where a person addresses each level before they are concerned with the next set of needs. The template carries well, such that Brent Ozar(@brento) even wrote about his own Hierarchy of Database Needs a while back.
So what’s my approach? To get the detail, you’ll need to come to my PASS session, but I’ll let the overview whet your appetite:
Survival – There are some factors database administrators must be concerned with. As guardians of the data, we have to ensure three things about our systems before we can worry about anything else:
- Reliable backups – You hear this ad nauseum, but it’s true. Without backups, we’re crossing the high wire without a net. Note, also, that these are “reliable”. You need to know more than your backups are happening, but can you find them and are they usable.
- Service Availability – Is SQL Server up? Is it responding to queries? While this seems like a “duh” moment, if our users can’t access their data, then we’re in almost as much trouble as we were if we can’t recover from a backup.
- Space – This is not long range capacity planning that we will worry about later down the road, but a validation that we’re not “red lined” for space. Because if we run out of space, we affect availability and use of our databases.
Knowledge – In order to identify what to monitor, we need to know what to be monitoring for, otherwise we’re wandering in the mountains without a map. We establish this by working with the business to create our Service Level Agreements. I wrote about SLAs a year ago and my approach is still the same:
- Availability – Users want to know their data is queryable, protected, and secure. We need to define our customer’s expectations for high availability, disaster protection, maintenance windows, and security.
- Performance – Users want their data fast, but we need to put definition around this. What defines a query as to slow? How long can things be blocked? What sort of resource usage is allowed within our environments?
- Support – While this only partially affects our monitoring, our users want to know who’s “throat to choke” if there’s an issue. For monitoring, that defines escalation patterns and critical/non-critical alerts.
Direction – Metrics and whether they’re to high or to low are commonly what DBAs think of when they discuss monitoring. Are my batches/second to high? What’s my I/O throughput? Page Life Expectancy? Wait types? The list goes on and on. However, like many things, DBAs want to put the cart before the horse and just start looking at stats. By dealing with SLAs first, we’ll be better equipped to monitor what’s important to the business rather than what’s important to us.
Actualization – After we know what to look for, it’s time to decide how we look for it, and this leads us into the discussion of tools. The problem is, there are a load of tools out there you can use. Do you go with a specialized third product? Maybe some larger, more generic system that integrates with other parts of the enterprise? Do you write your own, using what’s freely available and paying the cost in time to build? Whatever the case, having a list of metric needs equips us with the knowledge necessary to identify what tool set best suits our situation.
Understanding – One of the trickiest parts of monitoring is knowing what’s a problem and what is just normal behavior. Once our metrics are defined and our tools are set up, we need to collect baselines and map trends to understand the health of our enterprise. While our SLAs can give us a starting point, we need to study our environments over time.
Refinement – Once everything is in place, we can start the cycle of fine tuning our monitoring. Systems and processes change over time. New storage will need to be added and new applications brought on line. With we are able to periodically review our trends and anticipate future needs. Managing our metrics based on these changes and adapting our monitoring is an ongoing process and is never set in stone.
Just so you know, this is just the 30,000 foot view that gives administrators the basic map. At Summit I’ll discuss the territory in a little more detail as well as some scripts, templates, and additional information to help you with your own monitoring needs. I’m very excited to be sharing this at Summit and hope that you’ll all join me for it.

 I’m tweeting!
I’m tweeting!
Great post! You’ll have to give us a sneak peak of the preso before you go.
Does the business / management get any feedback out of the monitoring process? Or is just as simple as – “we met your SLA?” Sometimes it we be nice to frame monitoring within the business needs.
Not directly related to monitoring but with some similarities – there is a great post discussing DBA 102: Beyond the Basics that has great section on dealing with management :-)
Also where does “self-managing” or “self-healing” fit into the hierarchy of needs?
Cheers,
Jeff
[…] The Hierarchy of Monitoring Needs – Giving us a sneak peak of what to expect at SQL PASS, Mike Fal (Blog|Twitter) puts his own spin on the psychology of SQL Server monitoring. […]
Mike,
Execllent overview and I look forward to seeing your presentation in Charlotte, of course, if it is not at the same time as me presenting :)
I am reviewing your Partitioning presentation you did in Colorado Springs to implement at my current employer.
Thanks,
Thomas