 It’s been a while, but I want to wrap up my series on Azure SQL Databases and Powershell. In my last post, I talked about how you can make point in time backups of Azure SQL Databases using the Start-AzureSqlDatabaseExport. This process allows you to make a backup of your Azure SQL Database and store it as an Azure blob. You can then restore these backups using Start-AzureSqlDatabaseImport. It’s all very handy to manage your data within the Azure environment.
It’s been a while, but I want to wrap up my series on Azure SQL Databases and Powershell. In my last post, I talked about how you can make point in time backups of Azure SQL Databases using the Start-AzureSqlDatabaseExport. This process allows you to make a backup of your Azure SQL Database and store it as an Azure blob. You can then restore these backups using Start-AzureSqlDatabaseImport. It’s all very handy to manage your data within the Azure environment.
Now let’s talk about what I alluded to at the end of that post: using this process to migrate data from your traditional SQL Servers to Azure SQL databases. As we have previously discussed, Azure SQL Database does not support traditional backups as we are used to with regular SQL Server. While there’s a debate on whether or not these should be supported, the reality is that we need another process to handle this. This is where the export/import process comes in.
BACPACing
SQL Server Data Tools(SSDT) have always had a process to extract your database. There are two types of extracts you can perform:
- DACPAC – A binary file that contains the logical database schema and possibly the data. This file retains the platform version of the database (i.e. 2012, 2014, 2016).
- BACPAC – A binary file that contains the logical database schema and the data as insert statements. This stores the platform version, but is not locked into it.
The DACPAC extract is useful for managing your database code. These objects can be source controlled and, using SSDT, can be used to compare to a current database state and deploy changes. I’m a big fan of using DACPACs to manage my database code and maintain code consistency. I don’t use the data extract portion, but it’s there if you need it (more on this in a later blog post).
BACPACs are a little more limited. They contain the schema and your data in a logical state, as insert VALUE statements to populate your database objects. The advantage is you get a flexible package that can deploy a database and its data to almost any SQL Server platform (with some caveats, which we will get to). The disadvantages are that the BACPACs are not as efficient as native backups and are not transactionally consistent.
What this means is that BACPACs are not really suited for day to day backups of your database. They are intended to be a migration tool, especially if you are working with disparate versions of SQL Server. It is why they’re intended for moving databases to Azure SQL Database, because a BACPAC can move your database logically and you are not reliant on the underlying database architecture.
Which brings us to the caveat. While BACPACs allow us to move a database logically, it can not always take into account unsupported features. We can export a database from our SQL Server, but if we’re using something not supported in Azure SQL Database (such as CLR or Service Broker), then this migration will not work. If you are planning this sort of migration, you first need to review your databases for these issues.
Exporting Our Database
Enough about that, let’s get exporting. There are several ways to migrate your database, but we’re going to focus on Powershell and those cmdlets. We can use sqlpackage.exe to create the BACPAC, which is pretty easy (this is really one line, I’m separating it so it’s easier to read):
SqlPackage.exe
/action:Export
/SourceServerName:localhost
/SourceDatabaseName:AdventureWorks2012
/targetfile:'C:\temp\AW2012.bacpac'
Once we’ve got our .bacpac file, we need to get it up into Azure. For this we need a storage account, then it’s just a matter of copying the blob. For this, we will use the same storage container we used for the exports before. We will create a storage context for the storage account, then use Set-AzureStorageBlobContent to upload the .bacpac file.
$stctxt = (Get-AzureRmStorageAccount -ResourceGroupName test -Name msftest).Context
Set-AzureStorageBlobContent -File C:\TEMP\ADW2012.bacpac -Context $context -Container sqlexports
Liftoff to the Cloud
With our export loaded into Azure, we’re ready to import it into Azure SQL database. We need to first create a database to import the data into:
New-AzureRmSqlDatabase -ResourceGroupName 'IntroAzureSQL' -ServerName 'msf-sqldb' -Edition Basic -DatabaseName AWTEST
After this, it is just a matter of starting the import as we did previously. We need to create a connection context for our Azure SQL Database server, then start the import:
$cred = Get-Credential
$sqlctxt = New-AzureSqlDatabaseServerContext -ServerName msf-sqldb -Credential $cred
$request = Start-AzureSqlDatabaseImport -SqlConnectionContext $sqlctxt -StorageContext $context -StorageContainerName sqlexports -DatabaseName awtest -BlobName ADW2012.bacpac
Notice I save the output of Start-AzureSqlDatabaseImport into a variable. This is an object requesting the import request, which I can use to check on the import. Remember that calling the cmdlet starts an asynchronous process that will import the schema and data of the .bacpac into your newly created database. We’ll want to check on the process to identify when it completes.
Double Check Your Work
The one last thing to do is to verify the migration, which requires two checks: the schema and the data. For the schema, we will go back to sqlpackage.exe to perform a schema comparison. This is a two step process:
- Extract the source schema as a .dacpac
- Generate a deploy report targeting the Azure SQL database. If no changes are shown, the schemas match.
Extracting the schema as a .dacpac is a similar operation to extracting the schema as a .bacpac:
SqlPackage.exe /action:Extract `
/SourceServerName:localhost `
/SourceDatabaseName:AdventureWorks2012 `
/p:ExtractAllTableData=True `
/targetFile:C:\Temp\AW2012.dacpac
Generating a deploy report is a similar command, though we have a couple gotchas. First, we’re connecting to our Azure SQL database, so we need our login and password passed to the command. Second, .dacpacs store the database platfom version and will halt if there’s a possible incompatibility. So we need to declare AllowIncompatiblePlatform=True in our sqlpackage call to ignore this. We’ll still get a flag that there could be incompatibilities, but it will at least run the comparison for us:
SqlPackage.exe /action:DeployReport `
/SourceFile:C:\Temp\AW2012.dacpac `
/targetServerName:msf-sqldb.database.windows.net `
/targetDatabaseName:AWTEST `
/targetUser:"$($cred.UserName)" `
/targetPassword:"$($cred.GetNetworkCredential().Password)" `
/p:AllowIncompatiblePlatform=True `
/OutputPath:C:\temp\AWMigration.xml
The resulting .xml file will tell us what changes the deployment would have to make to get everything lined up. Since the goal here is to verify that everything got deployed correctly, we want this report to not have any changes. The desired output would look a little like this:

Since no changes are listed, there’s nothing to do and everything matches.
Checking your data can be a trickier proposition. For a basic “sniff test”, I just check the row counts of each table. For this, I have a query to check sys.partitions for heaps and clustered indexes (index_id is 0 or 1) and compares the source to the Azure SQL database to look for any differences:
$sql = "select
schema_name(schema_id) +'.'+ t.name as TableName
,p.Rows as Rows
from
sys.tables t
join (select * from sys.partitions where index_id in (0,1)) p on t.object_id = p.object_id
order by TableName"
$local = Invoke-Sqlcmd -ServerInstance localhost -Database AdventureWorks2012 -Query $sql
$azure = Invoke-Sqlcmd -ServerInstance msf-sqldb.database.windows.net -Database AWTEST -Query $sql -Username $cred.UserName -Password $cred.GetNetworkCredential().Password
$matches = @()
foreach($i in $local){
$matches += New-Object psobject -Property @{'TableName'=$i.TableName;'LocalRows'=$i.Rows;'AzureRows'=($azure | Where-Object {$_.TableName -eq $i.TableName}).Rows}
}
$matches | Where-Object {$_.LocalRows -ne $_.AzureRows}
Again, if everything worked correctly we shouldn’t get any output.
I should stress that these two checks do NOT replace thorough regression testing. These should give you a starting point to verify that your migration was successful, but you still will want to test your applications and processing.
The New Hotness
Now, while I would like for Microsoft to include some native cmdlets that accomplish these actions, it should be noted that sqlpackage.exe is a pretty solid tool. It can be used from the command line and wrapping PowerShell around it is still effective. The key is having something I can use from the command line so I can write repeatable scripts. This is important because Azure is driven by automation and, while we can use GUI tools and the portal, we won’t succeed long term in the cloud on these tools alone, so it’s important to understand all the options.


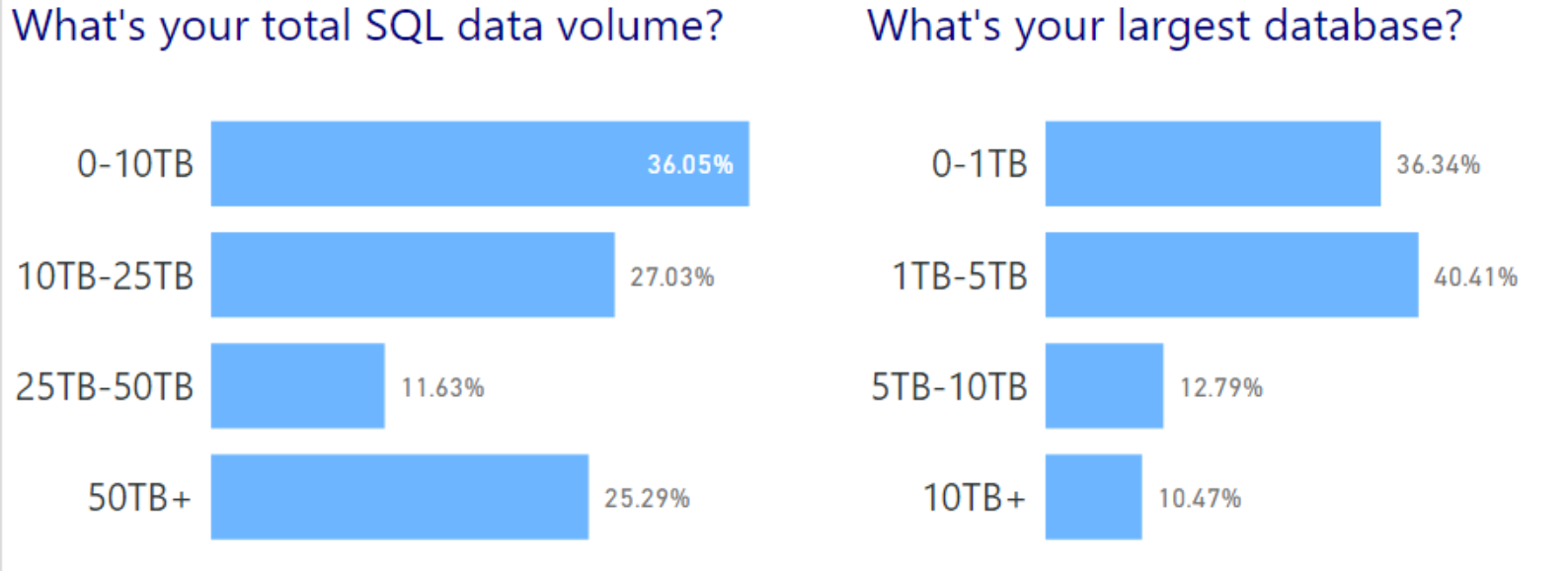
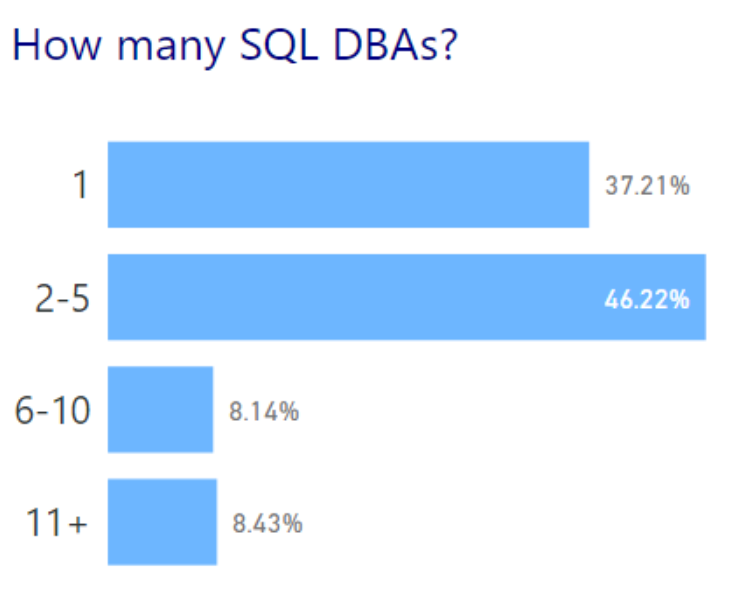
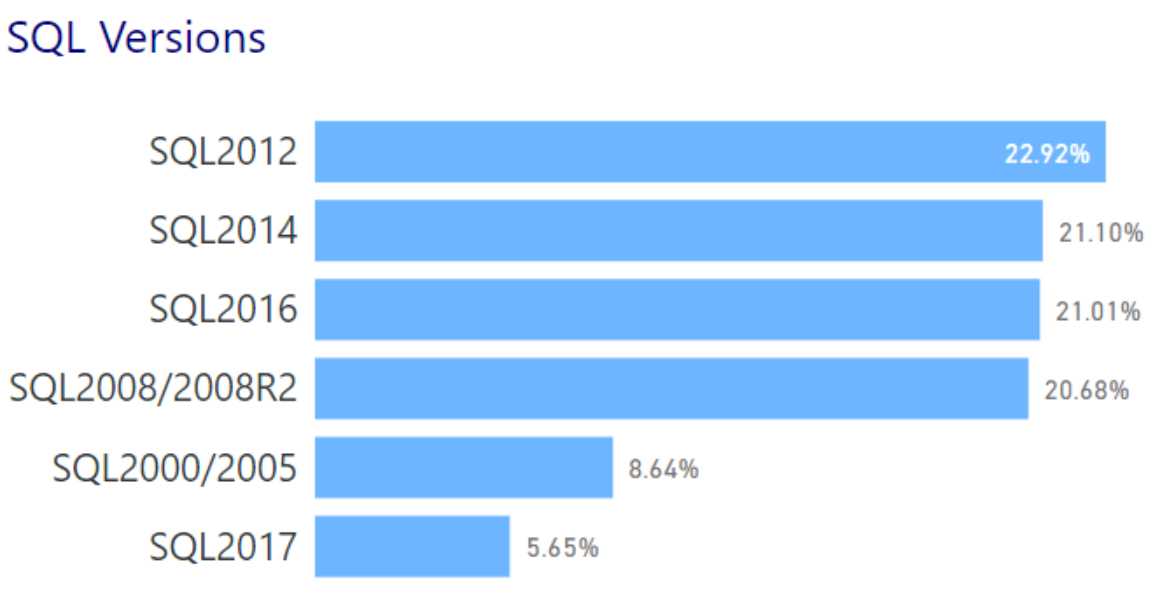
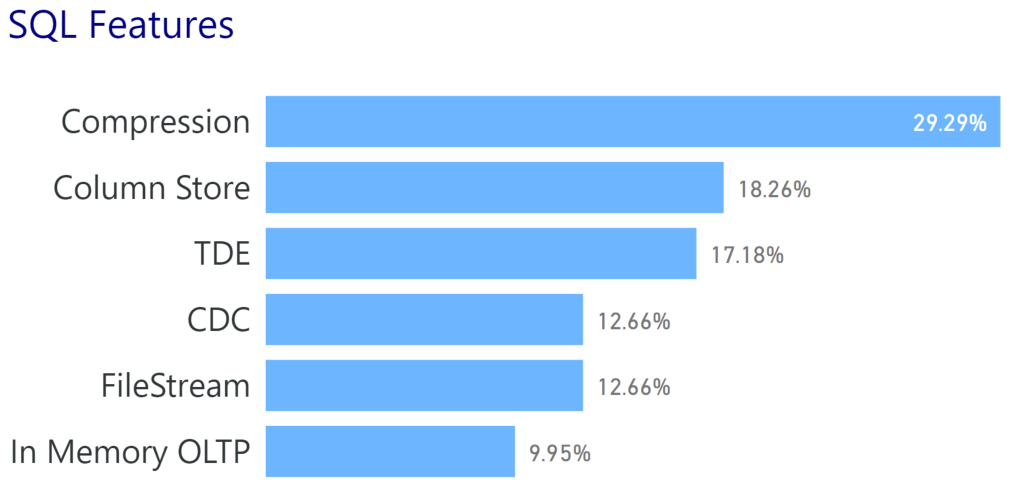









 I’m tweeting!
I’m tweeting!