
Recently I was doing some work with a friend around some database restores. It was pretty routine stuff. However, after one restore my friend came across something in the SQL Error Log that caught him by surprise. As part of the restore, there was a CHECKDB message for the restored database:
My friend’s first reaction was “why is SQL Server doing a DBCC CHECKDB as part of the restore?” He was concerned, because CHECKDB is a pretty hefty operation and this could really impact the restore time if he had to wait on a CHECKDB to complete. But the other confusing thing was that the date for the CHECKDB didn’t match up with the restore timing.
A Clean Start
Now I was pretty sure that the SQL restore didn’t actually run a CHECKDB, but I needed an explanation for this message. I figured I’d start with good old AdventureWorks2014 to test through the process. Also, since I needed to get in the guts of the restore, I broke out a few undocumented trace flags:
DBCC TRACEON(3014); DBCC TRACEON(3604); DBCC TRACEON(3605);
Trace flag 3014 is the important on, as it provides the details on what actually happens during a database restore. Once I turned these flags on, I ran an initial restore of the AdventureWorks2014 database to the name of AW2014_BASE and reviewed the output from TF 3014. I focused on everything from when the database was brought online to the completion of the restore.
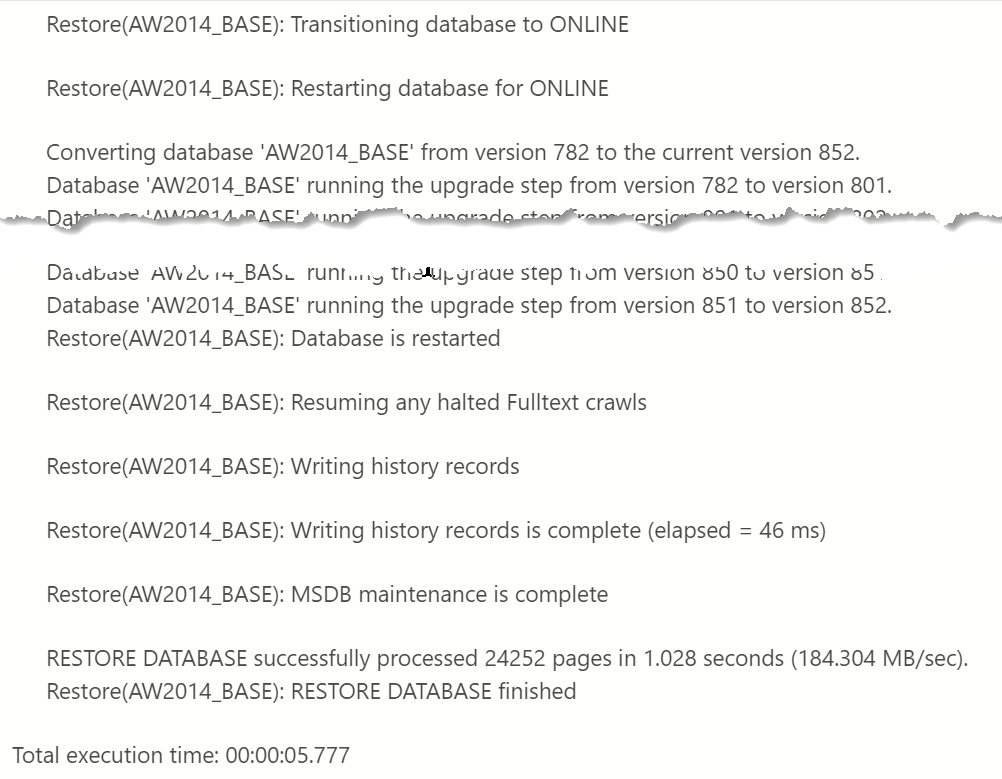
Notice that no where in this output do we see evidence of a CHECKDB command. So far, so good, right?
Checking our CHECKDB
My suspicion at this point is that the CHECKDB message found in a database restore was actually unrelated to the restore itself. The next step was to actually run a DBCC CHECKDB against my test database (and capture the time the DBCC was run).
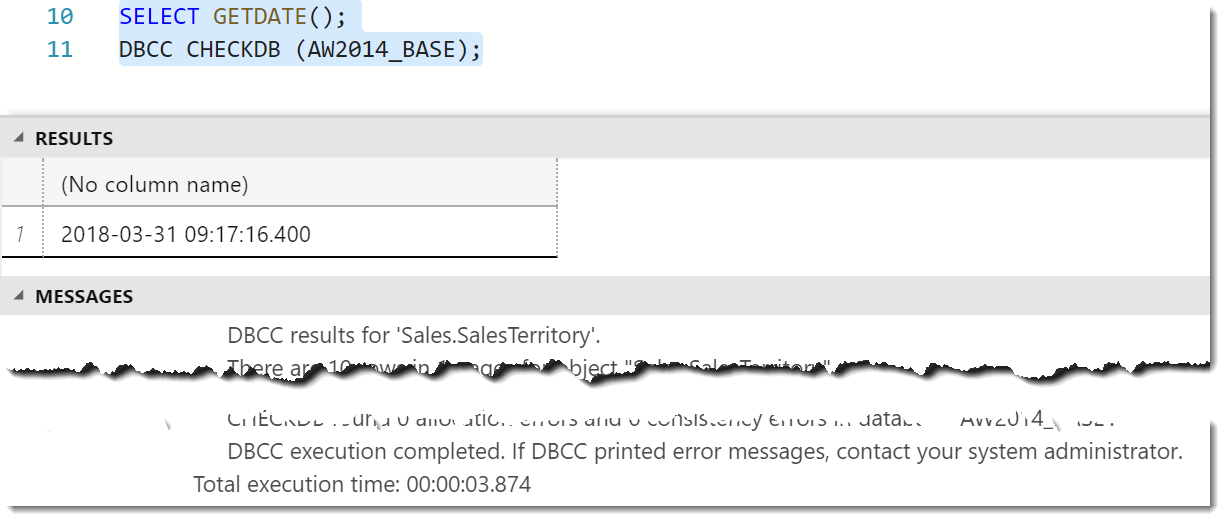
With this completed, it was time to do another backup and restore with my trace flags enabled to see what I got.
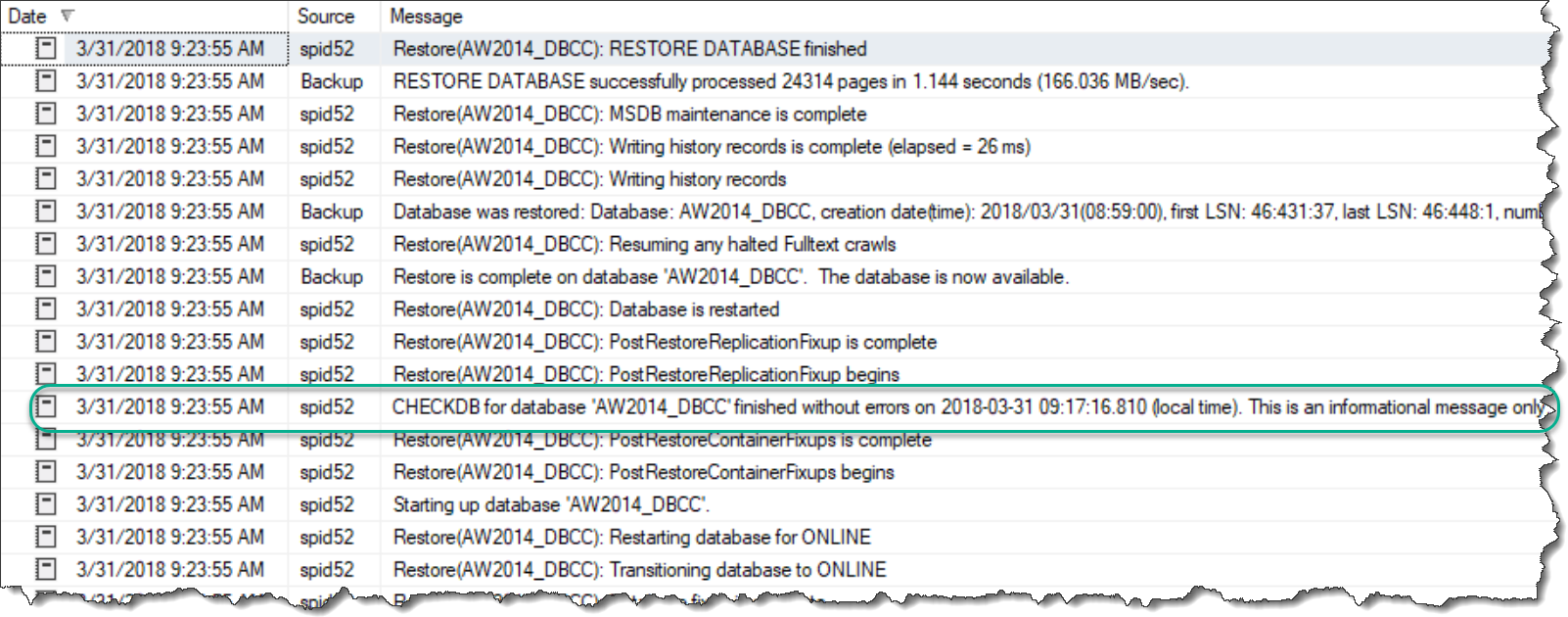
Lo and behold, our CHECKDB message is back. But what’s going on? Why did it appear here but not in the first restore? The key (as you might have already guessed) is to look at the datetime for the CHECKDB in the error log: 2018-03-31 09:17:16. This matches the time we actually ran DBCC prior to our backup. In fact, if we review the message output from the restore (and not the error log messages) for the same restore span, you’ll see there are no actual CHECKDB messages within the restore.
Mystery Solved
The answer here is pretty simple. When you restore a database, SQL Server is trying to help you by telling you the last time the database had a CHECKDB run against it. That’s actually why the message says “his is an informational message only; no user action is required.” However, for many folks not familiar with the process can be confused and jump to the conclusion that SQL Server is doing more than it should be. The key to clearing up these misconceptions is to use our tools to lift up the hood and see what’s going on internally. Once you look at these details, it’s pretty clear to see what’s happening and become better informed on how SQL Server works.

 I’m tweeting!
I’m tweeting!