
So far, I’ve talked about NoSQL’s use of key-value pairs for storage along with its partitioned nature. These two concepts are useful, but you’ve probably noticed that it can make querying a lot more difficult, particularly for aggregating data. That’s where the third and final concept that I want to discuss comes in to play, the process that non-relational data stores use to analyze all the data it has stored across its nodes: MapReduce.
At the core, MapReduce isn’t some wild concept. The idea is to marshall all of our compute resources to analyze and aggregate data. Simply put, there are two phases that a non-relational system will use to aggregate data:
-
Map – On each individual node, collect and aggregate the data that matches our predicate. Pass this to a higher node.
-
Reduce – Aggregate on a “master” node the values passed from the individual nodes. Once the work from all the individual nodes has been aggregated, we have our answer.
As with most of this NoSQL stuff, it is not rocket science. It does, however, make more sense if we visualize it. Let’s say, for example, we wanted a count of all our sales orders within a sales territory and we had a 3-node NoSQL cluster (platform is irrelevant). A basic MapReduce tree would look something like this:
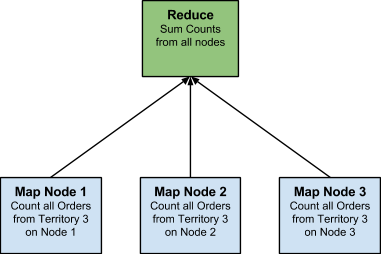
This isn’t all that much different than how SQL Server (or another RDBMS, for that matter) would process it. If we take the same concept and apply to a basic query from AdventureWorks, we can see the SQL approach to it:
select count(1) from sales.SalesOrderHeader where TerritoryID = 3
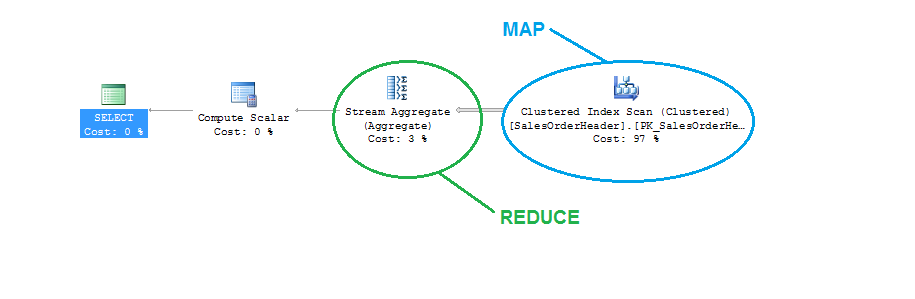
You can see from this basic query plan that the only real difference here is that the mapping piece happens on a single node (your instance) rather than multiple nodes. But otherwise, the process of gathering all the data we need to calculate and then calculating our total aggregate is the same. It’s the idea of scaling this out over multiple compute nodes that is the major difference.
And scaling is huge. 3-nodes is a piece of cake, but what if we had 10? Or 30? Or 100? Again, the idea is that non-relational data stores can handle terabytes and petabytes of data and you can scale out horizontally to meet those needs. When we do this, our MapReduce tree can scale to our needs, so we might get something like this:
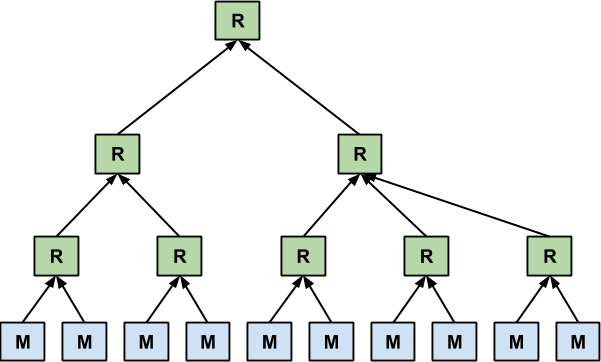
Notice the multiple reduce steps. Just as we can divide and conquer horizontally and collect data across that scale, we can also also do vertical scaling and have multiple reduce phases to further scale the load. It’s all part of the massively parallel processing model that NoSQL promotes.
There are disadvantages to this, but most of them boil down to the implementation. Primarily it’s driven around the need in many NoSQL platforms to write your own MapReduce functions using APIs or embedded languages (like JavaScript or platform specific functions). May platforms are working on SQL-like alternatives to ease this learning curve, but there’s still a lot of growth and maturity needed here and I’m not sure how standardized any of these options really are.
Of course, these MapReduce queries aren’t necessarily going to smoke an RDBMS in terms of performance. It’s all a matter of design and how you apply the tool. MapReduce processes are designed, primarily, for batch aggregation of massive amounts of data. Quantities of data that may not necessarily make sense to store in an RDBMS structure. As we always say in the database admin world, it depends. The goal here is to understand how this query process works so we can properly apply it to our own implementations.
Wrapping Up
Hopefully this three-parter has been helpful and educational for you. I’ve certainly learned a lot about non-relational databases over the past 6 months and my eyes have been opened to new ways to manage data. That’s really what we’re all here for, anyway. As the world has more and more data to manage, we as data professionals need to find ways to store it, manage it, and make it useful to those who need it. NoSQL is just another tool in our toolbox, a hammer to go with our RDBMS screwdriver. Both valuable, if we use them appropriately.
Before I move on, I did want to share some resources I’ve found helpful in getting my head around non-relational databases:
-
Seven Databases in Seven Weeks – I’m actually not done with this, but it’s a great book for getting your feet wet with several different types of databases. Be warned, this is not for the faint of heart and there’s a LOT you’re going to have to figure out on your own, but it will guide you through some basic concepts and use cases.
-
Martin Fowler’s Introduction to NoSQL – This is a great hour long presentation that talks about a lot of what I’ve covered here from a different angle. It’s got great information and explains things at a good level.
-
Ebay’s Tech Blog on Cassandra Data Modelling – Getting my head around how you model data in a Big Table structure was really, really hard. This two parter will help you figure this out.
I also want to thank Buck Woody(@BuckWoody) for opening my eyes to the world of the cloud and big(ger) data. It was partly from a conversation with him that I went down this path and the learning that has come out of it for me has been tremendous.

 I’m tweeting!
I’m tweeting!