
It’s been awhile since I’ve written a T-SQL Tuesday post, but thanks to Michael Swart(@MJSwart) for hosting this month’s edition. The request is simple enough: blog about some aspect of SQL Server 2016. This is actually a good opportunity for me to write about a feature I’ve been meaning to get to for some time now and just haven’t had the chance.
As I tell many people, I’ve been working with SQL Server since 1999 (version 7.0) and I can’t remember being more excited about a SQL Server release. 2016 has SO many cool features, but more than that, they are features that many people who use SQL Server have been asking for a while now. It is hard for me to simply blog about one feature since there are so many. However, there has been an improvement to Availability Groups that has not gotten a lot of coverage and I think it is a game changer, especially for those of us who have to manage AGs on a day to day basis: direct seeding.
Setting Up Replicas
In SQL Server 2012 and 2014, creating an Availability Group could take a significant amount of work. One of the more tedious tasks is setting up your replica databases. This is because that you need to restore your database to your replica node in a state close enough to the primary to allow synchronization to happen. It can take several log backup restores to hit that magic window where you can join the database on the secondary node. Then, you get to do it again on the next replica!
Enter direct seeding in 2016. With this feature you no longer have to do any of the restores. You simply create your replicas with direct seeding enabled, then when you add a database to the AG, SQL Server will directly seed the database to your replica nodes. It’s surprisingly simple.
How do we enable this magic? It’s part of the AG replica creation. We still need the prerequisites, so we’ll start with the following:
- Create a cluster
- Enable AlwaysOn for the SQL Service
- Create endpoints and grant permissions on those endpoints
- The database we’re adding must be in FULL recovery mode
I, unsurprisingly, have a Powershell script that will set this all up for me. Then we can create the Availability Group with the direct seeding setting. Currently, this is only supported using T-SQL (go wizard or Powershell support), but the syntax is documented in MSDN. Let’s start by creating our Availability Group:
CREATE AVAILABILITY GROUP [ENTERPRISE]
FOR
REPLICA ON 'PICARD' WITH (
ENDPOINT_URL = 'TCP://PICARD:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC
),
'RIKER' WITH (
ENDPOINT_URL = 'TCP://RIKER:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC
)
LISTENER 'ENTERPRISE' (WITH IP (('10.10.10.101','255.255.255.0')))
ALTER AVAILABILITY GROUP [ENTERPRISE] GRANT CREATE ANY DATABASE
--Run these on the secondary node
ALTER AVAILABILITY GROUP [ENTERPRISE] JOIN
ALTER AVAILABILITY GROUP [ENTERPRISE] GRANT CREATE ANY DATABASE
There are two important lines to call out here:
- SEEDING_MODE = Automatic
- ALTER AVAILABILITY [ENTERPRISE] GRANT CREATE DATABASE
The SEEDING_MODE is what enables direct seeding, but we need to grant the AG permission to create databases on the node as well. Then we add the database to the AG. At this point, though, we only have node. It’s time to add a second node and watch the magic happen.
Hands Off
Once we’ve created the AG, we just add the database to it:
ALTER AVAILABILITY GROUP [ENTERPRISE] ADD DATABASE [WideWorldImporters]
Once we’ve done this, SQL Server takes over and pushes the database out to the secondary replicas:
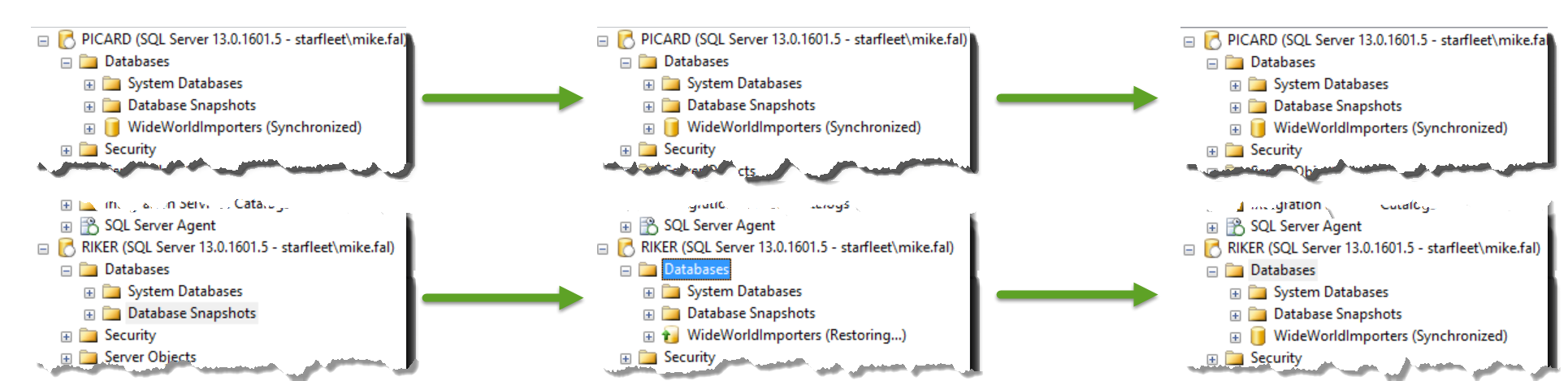
That’s it! SQL Server handles all the replication for you. All is not sunshine and rainbows, however. There are still some gotchas to keep in mind:
- You need to create the Availability Group with all its replicas at the start. You can not add replicas at a later point (I thought I had done this, but more recent testing was not working).
- The AG must also be set up before you add any databases. You can add the database as part of the AG creation or after, but you have to have all your nodes configured before adding the database to allow direct seeding to work.
- This is a data operation, so we “canna’ change tha’ laws a’ physics, Captain!” If you add a database to an AG with direct seeding, SQL Server still has to copy all the bits and bytes across the wire to the nodes. Which means nodes in other geographical locations could be a problem.
Overall, direct seeding is pretty cool, but still feels a little raw to me. Personally I’d like to be able to seed to a replica I add to the cluster if I desire, but that does not work right now. The lack of GUI and Powershell support (both cmdlets and SMO) is also disappointing. I can still use it, but I’d rather have a simpler way to do it.
For some additional reading, Erik Darling wrote about the exact same feature for T-SQL Tuesday as I did, so it gives you another view at it. Otherwise, that’s it for me on this T-SQL Tuesday. Thanks to Michael Swart for hosting this month. Make sure you check out the rest of the T-SQL Tuesday posts!

 I’m tweeting!
I’m tweeting!