SQL Agent jobs are a fundamental tool for managing our databases. Whether we are running regular backups, executing maintenance tasks, or performing a scheduled ETL process, being able to manage and run scheduled tasks is key to keeping our workload manageable. Of course, as our environment grows, keeping track of these jobs becomes harder and harder.
We can manage this growth by leveraging facets of Powershell. One aspect I continually advocate is Powershell’s ability to execute tasks easily across multiple servers. This means that our tools can easily adapt to the our growth. Additionally, since Powershell is a framework that supports different approaches, administrators can use a method most comfortable to them to accomplish their work.
Let’s take the case of reporting on failed jobs. Job failures usually mean that an administrator needs to troubleshoot an error, resolve it, and run the job again. Now, some jobs are critical and require immediate attention to fix. For this, the Agent provides error alerts and reporting that can execute at the time of failure. However, if it’s not as critical and can wait for someone to review it, we can build a reporting process that can be reviewed. I’d like to cover three techniques we can use in Powershell to accomplish this reporting and how you can leverage them yourself.
T-SQL and Powershell
The first technique is to simply combine a T-SQL query with some Powershell to execute across multiple instances and collect the results. Let’s start with the SQL query (borrowed from SQLMatters.com):
;WITH CTE_MostRecentJobRun AS
(
-- For each job get the most recent run (this will be the one where Rnk=1)
SELECT job_id
,run_status
,run_date
,run_time
,RANK() OVER (PARTITION BY job_id ORDER BY run_date DESC,run_time DESC) AS Rnk
FROM sysjobhistory
WHERE step_id=0
)
SELECT
@@SERVERNAME as Instance
,name AS [JobName]
,CONVERT(VARCHAR,DATEADD(S,(run_time/10000)*60*60 /* hours */
+((run_time - (run_time/10000) * 10000)/100) * 60 /* mins */
+(run_time - (run_time/100) * 100) /* secs */
,CONVERT(DATETIME,RTRIM(run_date),113)),100) AS [TimeRun]
FROM CTE_MostRecentJobRun MRJR
JOIN sysjobs SJ ON MRJR.job_id=sj.job_id
WHERE Rnk=1
AND run_status=0
AND [enabled] = 1
ORDER BY name
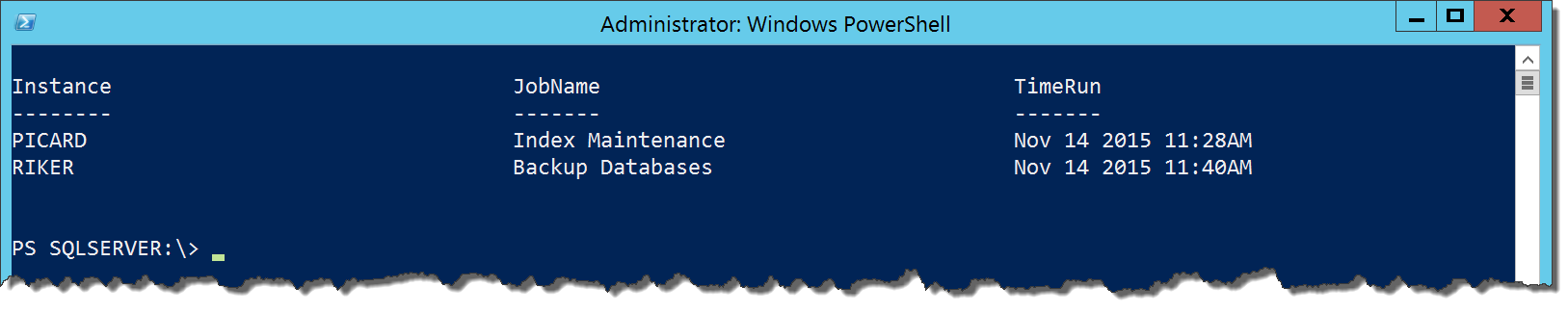
Running this within SQL Server Management Studio is easy enough and the query is exactly what we would expect. We want to run this against multiple servers. Now with a few lines of Powershell, we can create a report across all of our instances:
#I've already put the query into the $sql string variable.
#Not displayed here to save space
$servers = @('PICARD','RIKER','SPOCK','KIRK')
$servers | ForEach-Object {Invoke-Sqlcmd -ServerInstance $_ -Database msdb -Query $sql}
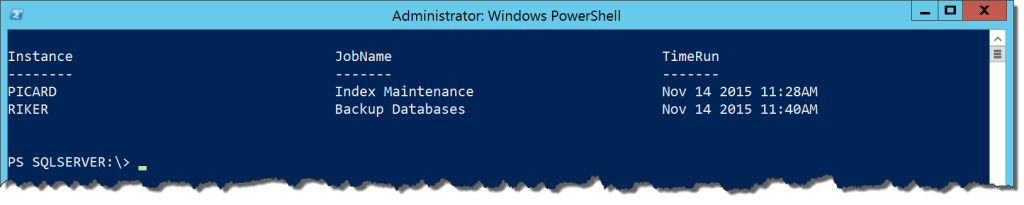
Pretty simple and it is flexible enough that all we have to do is add servers to our named list and we’re off to the races. If you want to make it even more dynamic, you could always leverage Central Management Server to populate your server list.
The SMO
This is effective, but I struggle a little with the SQL query. It’s good, but suffers from the structure of the jobs tables in MSDB. We have to account for that and it makes the SQL query a little convoluted. It would be helpful if we could reference a simple data set like the Job Activity Monitor in SSMS.
Of course, this is a leading question on my part. There is a way to do this and it is by leveraging the SQL Server Management Objects (SMO). This .Net library is the API interface for working with SQL Server and is what SSMS is built on. Because it is a .Net library, we can also access it through Powershell.
What we want from the SMO are the Smo.Agent.JobServer and Smo.Agent.Job classes. These represent the SQL Server Agent jobs and allow us to interact with everything within it. Using this and some handy Select-Object calls, we can accomplish what we want without the long T-SQL query:
[System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.Smo') | Out-Null
$servers = @('PICARD','RIKER','SPOCK','KIRK')
$servers | ForEach-Object {(New-Object Microsoft.SqlServer.Management.Smo.Server $_).JobServer.Jobs |
Where-Object {$_.LastRunOutcome -ne 'Succeeded'} |
Select-Object @{Name='Server';Expression={$_.Parent.Name}},Name,LastRunDate
}

We’ve accomplished the same task, but now without the complicated SQL query. Granted, this method is predicated on understanding the SMO object model, but this can be figured out using Get-Member and the MSDN pages that describe the methods and properties. Because everything in Powershell is an object, we can do so much more with the information contained within.
The Provider
The third method is actually the same as using the SMO. The SQL Server provider is an additional layer of abstraction that lets us browse SQL Server components as if they were a file system. It uses the SMO to do its work, so it will be handled in a similar way and give us the same results as the pure SMO. However, we can skip some of the .Net instantiation techniques in favor of a simple directory lookup:
$servers = @('PICARD','RIKER','SPOCK','KIRK')
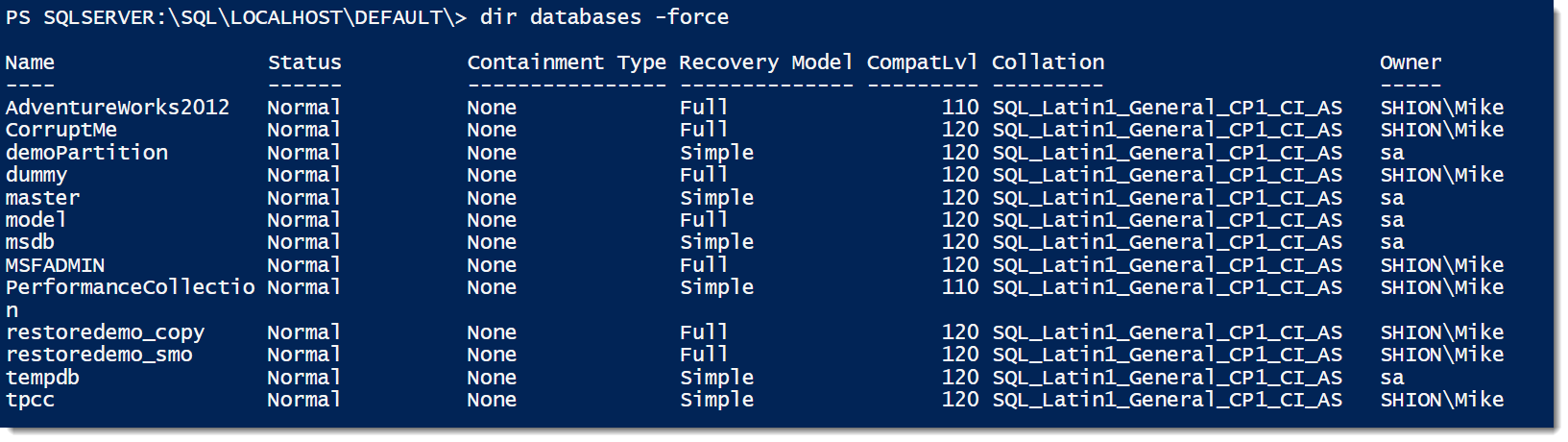
$servers | ForEach-Object {Get-ChildItem "SQLSERVER:\SQL\$_\DEFAULT\JobServer\Jobs\" |
Where-Object {$_.LastRunOutcome -ne 'Succeeded'} |
Select-Object @{Name='Server';Expression={$_.Parent.Name}},Name,LastRunDate
}
The output is exactly the same as the SMO, which makes sense because this method works in the same manner. However, because all the necessary libraries and objects are loaded when we load the provider (Import-Module SQLPS), we can skip the object instantiation. It removes another layer of complexity.
Wrapping Up
These three methods all give you the same amount of information, it’s up to you to decide which approach works best for your environment. For DBAs who want to work mostly with T-SQL and are still getting used to Powershell, the first option makes a lot of sense. For system administrators who have had SQL Server thrust upon them, the third option might work better as it doesn’t require any T-SQL knowledge. It’s all a matter of what is comfortable. However you want to work with your data, Powershell gives you the tools to get the information in a way that makes sense for you.





 I’m tweeting!
I’m tweeting!